and match it to the original symbol set:
Previous: 04-AffineCipher.html
“Obscurity and a competence.
That is the life that is best worth living”
- Mark Twain (real name: Samuel Langhorne Clemens)
document.querySelector('video').playbackRate = 1.2http://inventwithpython.com/cracking/ Chapters 16-20
Substitution ciphers
https://en.wikipedia.org/wiki/Substitution_cipher
https://crypto.interactive-maths.com/monoalphabetic-substitution-ciphers.html
There are many varieties of substitution cipher.
In the one variety we cover today,
a key is just a random ordering (permutation) of the
alphabet.
It is used to replace each letter of the symbol set,
with another matched by that random permutation of the same symbol set
(alphabet).
With the key being the length of the entire symbol set,
it is less easy to remember,
but much stronger than our previous algorithms!
It’s also a lot easier to program, and even to understand.
Randomize the order of an alphabet (symbol set),
and match it to the original symbol set:
To find the ciphertext character,
lookup in your matched random alphabet:

To find the original plaintext character:
reverse lookup in your matched random alphabet:

This is a very similar operation to encryption.
Mention/ask:
Permuting a string based on the order of another string is a very common
operation!
This is a common operation even outside of cryptography.
What resembles this?
How many permutations of the alphabet are there?
05-SubstitutionFrequency/alpha_rand.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import math
# Just the lower case letters:
print(math.factorial(26))
# When you include upper, lower, etc.
print(math.factorial(66))26! = 403,291,461,126,605,635,584,000,000
66! = 5.4 x 1092
Discussion question:
Would you guess we can reasonably brute force this key-space,
by trying them all for a standard encoding?
How many tries per second (or per minute, hour) would you guess your
laptop can perform?
For an alphabet of 26 (which is low, considering most encodings like
ASCII, UTF-8/16):
P: \(\mathbb{Z}_{26} = \{0,
1, 2, \ldots, 25 \}\)
C: \(\mathbb{Z}_{26} = \{0,
1, 2, \ldots, 25 \}\)
K: 26! = 403,291,461,126,605,635,584,000,000 orders on
symbol set of 26.
E: the encryption function is just indexing
lookup
E(k, x) = key_set[index of char in symbol_set]
D: the decryption function is just the reverse indexing
lookup
E(k, x) = symbol_set[index of char in key_set]
The encryption and decryption functions are very easy to code, and
fast.
It’s just simple indexing!
Trace of simpleSubCipher.py
05-SubstitutionFrequency/simpleSubCipher.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Simple Substitution Cipher
# https://www.nostarch.com/crackingcodes (BSD Licensed)
import sys, random
LETTERS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
def main() -> None:
myMessage = "If a man is offered a fact which goes against his inst\
incts, he will scrutinize it closely, and unless the evidence is overwh\
elming, he will refuse to believe it. If, on the other hand, he is offe\
red something which affords a reason for acting in accordance to his in\
stincts, he will accept it even on the slightest evidence. The origin o\
f myths is explained in this way. -Bertrand Russell"
myKey = "LFWOAYUISVKMNXPBDCRJTQEGHZ"
myMode = "encrypt" # Set to either 'encrypt' or 'decrypt'.
if not keyIsValid(myKey):
sys.exit("There is an error in the key or symbol set.")
if myMode == "encrypt":
translated = encryptMessage(myKey, myMessage)
elif myMode == "decrypt":
translated = decryptMessage(myKey, myMessage)
print("Using key %s" % (myKey))
print("The %sed message is:" % (myMode))
print(translated)
def keyIsValid(key: str) -> bool:
keyList = list(key)
lettersList = list(LETTERS)
keyList.sort()
lettersList.sort()
return keyList == lettersList
def encryptMessage(key: str, message: str) -> str:
return translateMessage(key, message, "encrypt")
def decryptMessage(key: str, message: str) -> str:
return translateMessage(key, message, "decrypt")
def translateMessage(key: str, message: str, mode: str) -> str:
translated = ""
charsA = LETTERS
charsB = key
if mode == "decrypt":
# For decrypting, we can use the same code as encrypting. We
# just need to swap where the key and LETTERS strings are used.
charsA, charsB = charsB, charsA
# Loop through each symbol in message:
for symbol in message:
if symbol.upper() in charsA:
# Encrypt/decrypt the symbol:
symIndex = charsA.find(symbol.upper())
if symbol.isupper():
translated += charsB[symIndex].upper()
else:
translated += charsB[symIndex].lower()
else:
# Symbol is not in LETTERS; just add it
translated += symbol
return translated
def getRandomKey() -> str:
key = list(LETTERS)
random.shuffle(key)
return "".join(key)
if _name_ == "_main_":
main()
Discussion question:
Once you have cracked one letter,
does it allow inference to crack the rest fully,
as it did with Caesar?
Once you have cracked one letter,
does it make cracking the remaining easier?
Does this make you think of any general strategies for cracking?
https://en.wikipedia.org/wiki/Frequency_analysis
Frequency analysis comes in a variety of flavors,
two of which include:
1. word frequency analysis, and
2. letter frequency analysis.
This analysis is only possible when spaces are not encrypted…
or can be easily decrypted first.
Let’s examine the word pattern of the cipherword, HGHHU
Potential mappings
HGHHU
=====
PUPPY
MOMMY
BOBBY
LULLS
NANNYMatching words should:
be five letters long,
the first, third, and fourth letters should be the same,
have exactly three different letters, and
the first, second, and fifth letters should all be different.
Word pattern of all of these is 0.1.0.0.2
Check out these (in order):
05-SubstitutionFrequency/dictionary.txt
wordPatterns.py
05-SubstitutionFrequency/wordPatterns.py
(one big python dictionary built from the English dictionary)
makeWordPatterns.py
05-SubstitutionFrequency/makeWordPatterns.py
(trace this one briefly)
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Makes the wordPatterns.py File
# https://www.nostarch.com/crackingcodes (BSD Licensed)
# Creates wordPatterns.py based on the words in our dictionary
# text file, dictionary.txt. (Download this file from
# https://invpy.com/dictionary.txt)
import pprint
def getWordPattern(word: str) -> str:
# Returns a string of the pattern form of the given word.
# e.g. '0.1.2.3.4.1.2.3.5.6' for 'DUSTBUSTER'
word = word.upper()
nextNum = 0
letterNums = {}
wordPattern = []
for letter in word:
if letter not in letterNums:
letterNums[letter] = str(nextNum)
nextNum += 1
wordPattern.append(letterNums[letter])
return ".".join(wordPattern)
def main() -> None:
allPatterns = {}
fo = open("dictionary.txt")
wordList = fo.read().split("\n")
fo.close()
for word in wordList:
# Get the pattern for each string in wordList:
pattern = getWordPattern(word)
if pattern not in allPatterns:
allPatterns[pattern] = [word]
else:
allPatterns[pattern].append(word)
# This is code that writes code. The wordPatterns.py file contains
# one very, very large assignment statement:
fo = open("wordPatterns.py", "w")
fo.write("allPatterns = ")
fo.write(pprint.pformat(allPatterns))
fo.close()
if _name_ == "_main_":
main()With spaces un-encrypted,
hacking the simple substitution cipher is relatively computationaly easy
using word patterns.
We can summarize the major steps of the hacking process as
follows.
Overall, it is a process of logical inference about possible
mappings:
The more cipherwords in a ciphertext,
the more likely it is for the mappings to overlap with one
another,
and the fewer the potential decryption letters for each
cipherletter.
This means that in this plaintext-spaces version of the simple
substitution cipher,
the longer the ciphertext message,
the easier it is to hack.
Check out simpleSubHacker.py on your own (no full trace
in class).
05-SubstitutionFrequency/simpleSubHacker.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Simple Substitution Cipher Hacker
# https://www.nostarch.com/crackingcodes (BSD Licensed)
import re, copy, simpleSubCipher, wordPatterns, makeWordPatterns
from typing import Dict, List, Union
LETTERS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
nonLettersOrSpacePattern = re.compile("[^A-Z\s]")
def main() -> None:
message = "Sy l nlx sr pyyacao l ylwj eiswi upar lulsxrj isr sxrjsx\
wjr, ia esmm rwctjsxsza sj wmpramh, lxo txmarr jia aqsoaxwa sr pqaceiam\
nsxu, ia esmm caytra jp famsaqa sj. Sy, px jia pjiac ilxo, ia sr pyyaca\
o rpnajisxu eiswi lyypcor l calrpx ypc lwjsxu sx lwwpcolxwa jp isr sxrj\
sxwjr, ia esmm lwwabj sj aqax px jia rmsuijarj aqsoaxwa. Jia pcsusx py \
nhjir sr agbmlsxao sx jisr elh. -Facjclxo Ctrramm"
# Determine the possible valid ciphertext translations:
print("Hacking...")
letterMapping = hackSimpleSub(message)
# Display the results to the user:
print("Mapping:")
print(letterMapping)
print()
print("Original ciphertext:")
print(message)
print()
print("Copying hacked message to clipboard:")
hackedMessage = decryptWithCipherletterMapping(message, letterMapping)
print(hackedMessage)
def getBlankCipherletterMapping() -> Dict[str, List[str]]:
# Returns a dictionary value that is a blank cipherletter mapping.
return {
"A": [],
"B": [],
"C": [],
"D": [],
"E": [],
"F": [],
"G": [],
"H": [],
"I": [],
"J": [],
"K": [],
"L": [],
"M": [],
"N": [],
"O": [],
"P": [],
"Q": [],
"R": [],
"S": [],
"T": [],
"U": [],
"V": [],
"W": [],
"X": [],
"Y": [],
"Z": [],
}
def addLettersToMapping(
letterMapping: Dict[str, List[str]], cipherword: str, candidate: str
) -> None:
# The `letterMapping` parameter is a "cipherletter mapping" dictionary
# value that the return value of this function starts as a copy of.
# The `cipherword` parameter is a string value of the ciphertext word.
# The `candidate` parameter is a possible English word that the
# cipherword could decrypt to.
# This function adds the letters of the candidate as potential
# decryption letters for the cipherletters in the cipherletter
# mapping.
for i in range(len(cipherword)):
if candidate[i] not in letterMapping[cipherword[i]]:
letterMapping[cipherword[i]].append(candidate[i])
def intersectMappings(
mapA: Dict[str, List[str]], mapB: Dict[str, List[str]]
) -> Dict[str, List[str]]:
# To intersect two maps, create a blank map, and then add only the
# potential decryption letters if they exist in BOTH maps.
intersectedMapping = getBlankCipherletterMapping()
for letter in LETTERS:
# An empty list means "any letter is possible". In this case just
# copy the other map entirely.
if mapA[letter] == []:
intersectedMapping[letter] = copy.deepcopy(mapB[letter])
elif mapB[letter] == []:
intersectedMapping[letter] = copy.deepcopy(mapA[letter])
else:
# If a letter in mapA[letter] exists in mapB[letter], add
# that letter to intersectedMapping[letter].
for mappedLetter in mapA[letter]:
if mappedLetter in mapB[letter]:
intersectedMapping[letter].append(mappedLetter)
return intersectedMapping
def removeSolvedLettersFromMapping(
letterMapping: Dict[str, List[str]]
) -> Dict[str, List[str]]:
# Cipherletters in the mapping that map to only one letter are
# "solved" and can be removed from the other letters.
# For example, if 'A' maps to potential letters ['M', 'N'], and 'B'
# maps to ['N'], then we know that 'B' must map to 'N', so we can
# remove 'N' from the list of what 'A' could map to. So 'A' then maps
# to ['M']. Note that now that 'A' maps to only one letter, we can
# remove 'M' from the list of letters for every other
# letter. (This is why there is a loop that keeps reducing the map.)
loopAgain = True
while loopAgain:
# First assume that we will not loop again:
loopAgain = False
# `solvedLetters` will be a list of uppercase letters that have one
# and only one possible mapping in `letterMapping`:
solvedLetters = []
for cipherletter in LETTERS:
if len(letterMapping[cipherletter]) == 1:
solvedLetters.append(letterMapping[cipherletter][0])
# If a letter is solved, than it cannot possibly be a potential
# decryption letter for a different ciphertext letter, so we
# should remove it from those other lists:
for cipherletter in LETTERS:
for s in solvedLetters:
if (
len(letterMapping[cipherletter]) != 1
and s in letterMapping[cipherletter]
):
letterMapping[cipherletter].remove(s)
if len(letterMapping[cipherletter]) == 1:
# A new letter is now solved, so loop again.
loopAgain = True
return letterMapping
def hackSimpleSub(message: str) -> Dict[str, List[str]]:
intersectedMap = getBlankCipherletterMapping()
cipherwordList = nonLettersOrSpacePattern.sub("", message.upper()).split()
for cipherword in cipherwordList:
# Get a new cipherletter mapping for each ciphertext word:
candidateMap = getBlankCipherletterMapping()
wordPattern = makeWordPatterns.getWordPattern(cipherword)
if wordPattern not in wordPatterns.allPatterns:
continue # This word was not in our dictionary, so continue.
# Add the letters of each candidate to the mapping:
for candidate in wordPatterns.allPatterns[wordPattern]:
addLettersToMapping(candidateMap, cipherword, candidate)
# Intersect the new mapping with the existing intersected mapping:
intersectedMap = intersectMappings(intersectedMap, candidateMap)
# Remove any solved letters from the other lists:
return removeSolvedLettersFromMapping(intersectedMap)
def decryptWithCipherletterMapping(
ciphertext: str, letterMapping: Dict[str, List[str]]
) -> str:
# Return a string of the ciphertext decrypted with the letter mapping,
# with any ambiguous decrypted letters replaced with an _ underscore.
# First create a simple sub key from the letterMapping mapping:
key = ["x"] * len(LETTERS)
for cipherletter in LETTERS:
if len(letterMapping[cipherletter]) == 1:
# If there's only one letter, add it to the key.
keyIndex = LETTERS.find(letterMapping[cipherletter][0])
key[keyIndex] = cipherletter
else:
ciphertext = ciphertext.replace(cipherletter.lower(), "_")
ciphertext = ciphertext.replace(cipherletter.upper(), "_")
key_str = "".join(key)
# With the key we've created, decrypt the ciphertext:
return simpleSubCipher.decryptMessage(key_str, ciphertext)
if _name_ == "_main_":
main()What about letter frequency?
Ask:
What are the two most common letters?
Hint:
Think about this for a possible future assignment!!
That first example substitution cipher is a weak version,
since it does not encrypt spaces.
Ask:
Ideally, which symbols in our set should be encrypted?
How do we crack this without spaces?
Do any other characters help us,
if they are not encrypted?
++++++++++++++++++++++++++
Cahoot-05.1
Pronounced “veezhehnair”.
https://en.wikipedia.org/wiki/Vigen%C3%A8re_cipher
https://en.wikipedia.org/wiki/Polyalphabetic_cipher
The Italian cryptographer Giovan Battista Bellaso described the
Vigenère cipher in 1553,
but it was eventually named after the French diplomat Blaise de
Vigenère,
one of many people who reinvented the cipher in subsequent years.
It was known as “le chiffre indéchiffrable,”
which means “the indecipherable cipher.”
It remained unbroken until British polymath Charles Babbage broke it in
the 19th century.
https://en.wikipedia.org/wiki/Charles_Babbage
Babbage originated the concept of a digital programmable computer.
A number of the earliest minds in computing were cryptographers!
5 different Caesar keys,
progressively rotated in a shifting window through the message:
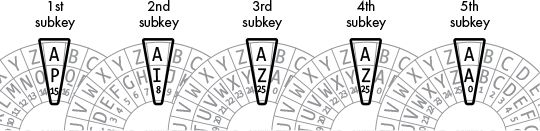
Number the alphabet:

A rotating key:
COMMONSENSEISNOTSOCOMMON
PIZZAPIZZAPIZZAPIZZAPIZZKey PIZZA to encrypt statement at left:
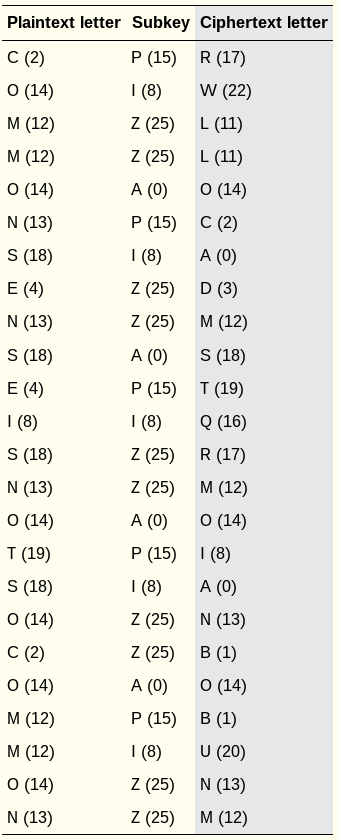
To compute one manually, having an easy Caesar lookup table
helps:

This table is just an easy reference for all the Caesar mappings,
if you’re doing it in the field by hand.
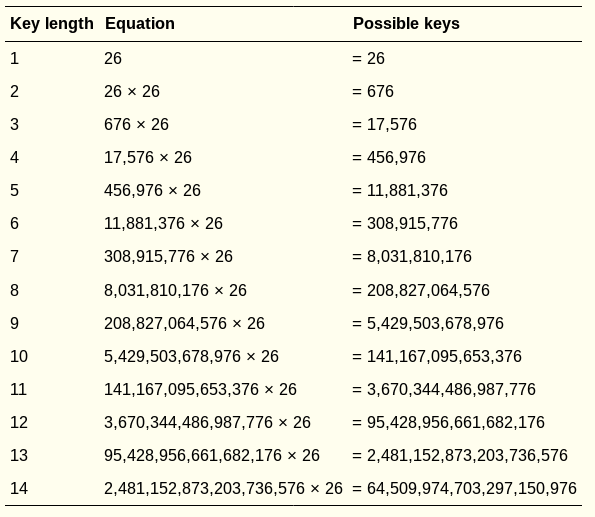
Longer Vigenère Keys Are More Secure!
What is the size of the keyspace?
Starting at the bottom,
for every additional letter the key has,
the number of possible keys multiplies by 26:
Generaly, symbol_set_size
key_len
Ask:
What is the upper limit of key length?
Is there an interaction between key length and message length?
Does it hurt to have a key shorter than your message length?
Does it help to have a key equal to your message length?
Does it help more to have a key longer than your message length?
These questions are actually critically important questions in cryptography theory.
Cursory trace of vigenereCipher.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Vigenere Cipher (Polyalphabetic Substitution Cipher)
# https://www.nostarch.com/crackingcodes (BSD Licensed)
LETTERS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
def main() -> None:
# This text can be copy/pasted from https://invpy.com/vigenereCipher.py:
myMessage = """If there is no struggle there is no progress. Those \
who profess to favor freedom and yet deprecate agitation are men who wa\
nt crops without plowing up the ground; they want rain without thunder \
and lightning. They want the ocean without the awful roar of its many w\
aters. This struggle may be a moral one, or it may be a physical one, a\
nd it may be both moral and physical, but it must be a struggle. Power \
concedes nothing without a demand. It never did and it never will. -- F\
rederick Douglass"""
myKey = "ASIMOV"
myMode = "encrypt" # Set to either 'encrypt' or 'decrypt'.
if myMode == "encrypt":
translated = encryptMessage(myKey, myMessage)
elif myMode == "decrypt":
translated = decryptMessage(myKey, myMessage)
print("%sed message:" % (myMode.title()))
print(translated)
print()
print("The message has been copied to the clipboard.")
def encryptMessage(key: str, message: str) -> str:
return translateMessage(key, message, "encrypt")
def decryptMessage(key: str, message: str) -> str:
return translateMessage(key, message, "decrypt")
def translateMessage(key: str, message: str, mode: str) -> str:
translated = [] # Stores the encrypted/decrypted message string.
keyIndex = 0
key = key.upper()
for symbol in message: # Loop through each symbol in message.
num = LETTERS.find(symbol.upper())
if num != -1: # -1 means symbol.upper() was not found in LETTERS.
if mode == "encrypt":
num += LETTERS.find(key[keyIndex]) # Add if encrypting.
elif mode == "decrypt":
num -= LETTERS.find(key[keyIndex]) # Subtract if decrypting.
num %= len(LETTERS) # Handle any wraparound.
# Add the encrypted/decrypted symbol to the end of translated:
if symbol.isupper():
translated.append(LETTERS[num])
elif symbol.islower():
translated.append(LETTERS[num].lower())
keyIndex += 1 # Move to the next letter in the key.
if keyIndex == len(key):
keyIndex = 0
else:
# Append the symbol without encrypting/decrypting.
translated.append(symbol)
return "".join(translated)
# If vigenereCipher.py is run (instead of imported as a module) call
# the main() function.
if _name_ == "_main_":
main()
Methods include dictionary and frequency analysis:
Just try all the words in the dictionary as keys:
Briefly glance at vigenereDictionaryHacker.py
05-SubstitutionFrequency/vigenereDictionaryHacker.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Vigenere Cipher Dictionary Hacker
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
import detectEnglish, vigenereCipher
from typing import Optional
def main() -> None:
ciphertext = """Tzx isnz eccjxkg nfq lol mys bbqq I lxcz."""
hackedMessage = hackVigenereDictionary(ciphertext)
if hackedMessage is not None:
print("Copying hacked message to clipboard:")
print(hackedMessage)
else:
print("Failed to hack encryption.")
def hackVigenereDictionary(ciphertext: str) -> Optional[str]:
fo = open("dictionary.txt")
words = fo.readlines()
fo.close()
for word in words:
word = word.strip() # Remove the newline at the end.
decryptedText = vigenereCipher.decryptMessage(word, ciphertext)
if detectEnglish.isEnglish(decryptedText, wordPercentage=40):
# Check with user to see if the decrypted key has been found:
print()
print("Possible encryption break:")
print("Key " + str(word) + ": " + decryptedText[:100])
print()
print("Enter D for done, or just press Enter to continue breaking:")
response = input("> ")
if response.upper().startswith("D"):
return decryptedText
return None
if _name_ == "_main_":
main()Ask:
What if your key is not a dictionary word?
Pros, cons?
What is the ultimate conclusion in choosing a key for this cipher??
General goal:
Cull/prune/reduce the key-space one needs to search.
Before pruning:
The number of keys to try includes all 1-letter keys, all 2-letter, all
3-letter, etc.,
After pruning:
How many keys?
Kasiski examination
https://en.wikipedia.org/wiki/Kasiski_examination
If the key happened to align with a repeated word (like ‘the’
perhaps),
then there would be a repeated pattern.
abcdeabcdeabcdeabcdeabcdeabcdeabc
crypto is short for cryptographyAsk:
Will this always work?
Under what conditions does it work better?
Process:
The Kasiski examination involves looking for strings of characters that
are repeated in the ciphertext.
The strings should be three characters long, or more, for the
examination to be successful.
Then, the distances between consecutive occurrences of the strings are
likely to be multiples of the length of the keyword.
Thus, finding more repeated strings narrows down the possible lengths of
the keyword,
since we can take the greatest common divisor of all the distances.
For example,
if you encrypted the plaintext THECATISOUTOFTHEBAG with the
key SPILLTHEBEANS,
you’d get:
plaintext->
THECATISOUTOFTHEBAG
SPILLTHEBEANSSPILLT
<-key

Notice that the letters LWM repeat twice.
The reason is that in the ciphertext,
LWM is the plaintext word THE encrypted using the same
letters of the key,
SPI, because the key happens to repeat at the second
THE.
Count the letters between all repeats,
from start to start of each repeat:
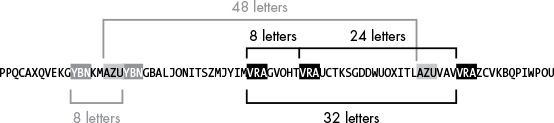
How long is the key likely to be above?
++++++++++++++++++++++++++
Cahoot-05.2
To illustrate multiple possibilities,
encrypt top row/plaintext (below) with two keys:
one 9 letters long on the left, and
one 3 letters long on the right:

Observations are candidate key lengths,
but observations also include factors of the key length:

Now, how many keys must we try?
All 2-letter, all 4-letter, all 8 letter, and less likely 12.
Ask:
This interval frequency is likely helpful for the Vigenère with a
reasonable key length,
but does it help for the mono-alphabetic substitution above (a possible
upcoming homework)?
What happens when the key length is the length of the message?
Is it stronger, and if so, how much?
Is it weaker, and if so, how much?
Does any word-frequency statistical method still help then?
How might we crack that encryption?
Might trying crack you…?
Once we have a hypothesis about key length,
then we need to crack each Caesar rotation
(one for each letter of the key).
Letter frequency analysis
If for example, we have a key length of 4 (e.g.,
CRYP),
now we have 4 sets of letters:
C - encrypts every 4th letter, starting at 1
R - encrypts every 4th letter, starting at 2
Y - encrypts every 4th letter, starting at 3
P - encrypts every 4th letter, starting at 4
Each of the above letters creates a Caesar encryption.
How many keys must we try to guarantee we see the plaintext for a single
Caesar?
How does this compound for the entire set of Caesar keys?
Is brute force tractable?
Is brute force necessary?
How do we cull the pool of keys to try?
What is a likely feature of the plaintext but not of the other 25
rotations?
Letter frequency in a corpus of English text:
The same plot, but sorted by frequency:
Ask:
In code, what is a reasonable metric for whether a block of text has an
observed frequency that matches the mean above?
The book uses a binned approach, asking whether frequent letters fall
into frequent or infrequent “categories”
Statically, can we do better?
Is there an objective best metric?
Letter-wise rank, count?
What is a corpus of text?
What is a representative corpus?
Once we have chosen the n most likely candidates for each
position,
then we can then finally brute force the remaining set!
Trace $ pudb3 vigenereHacker.py on your own:
05-SubstitutionFrequency/vigenereHacker.py
05-SubstitutionFrequency/freqAnalysis.py
(we’re back with version 2)
We used two frequency methods to crack the Vigenere, and a
word-frequency method to crack the mono-alphabetic substitution with
spaces not encyrpted.
How can we crack the mono-alphabetic substitution with spaces
encrypted?
You can do it with a simple spreadsheet, by hand, below:
Next: 06-OneTimePad.html