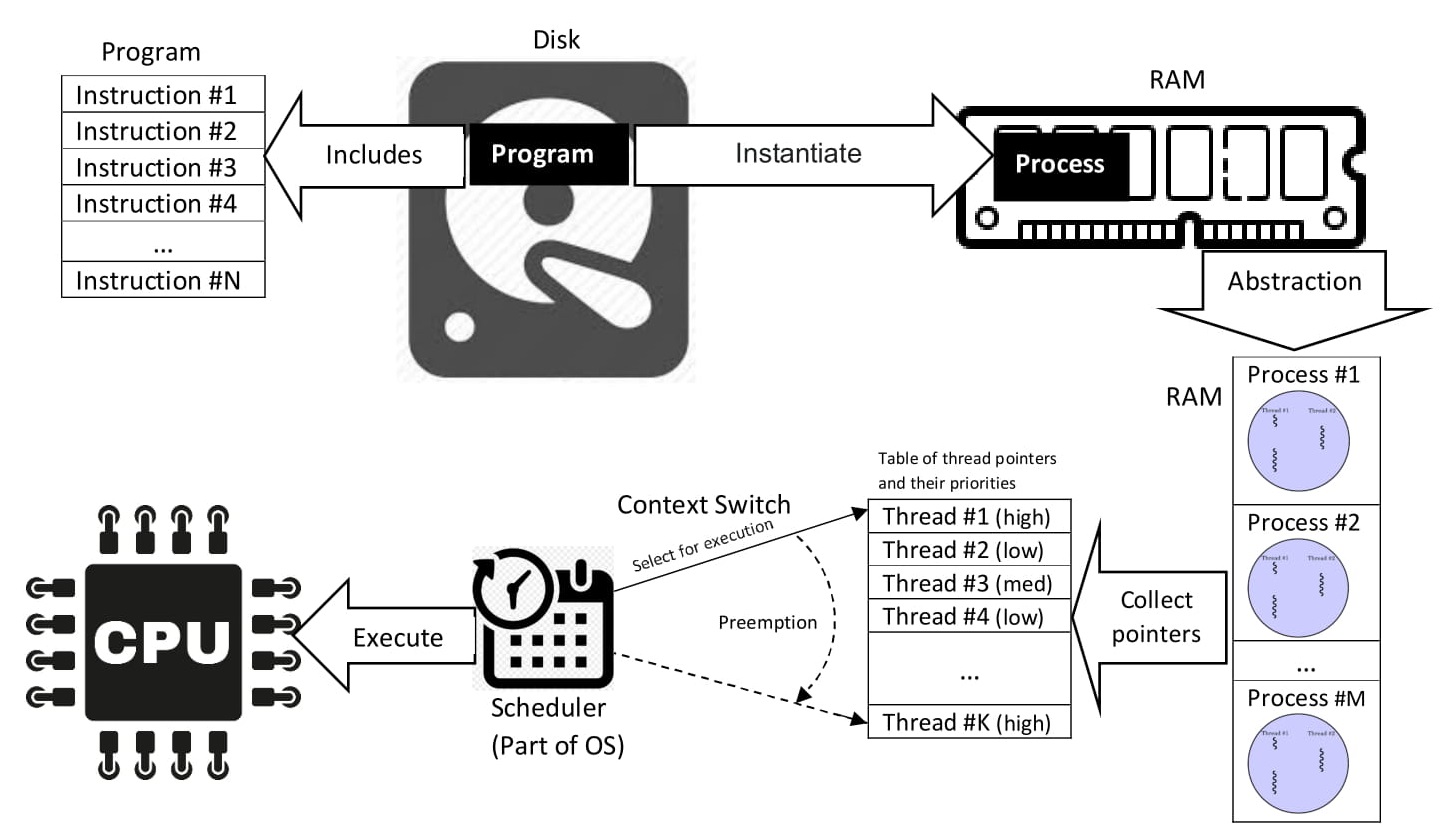
to efficiently manage all parts of the system.
It presents the user with an interface, or virtual machine,
that is easier to understand and program.
This layer of software is the operating system.
Q: Why did the CPU kill the operating system?
A: It was executing instructions…
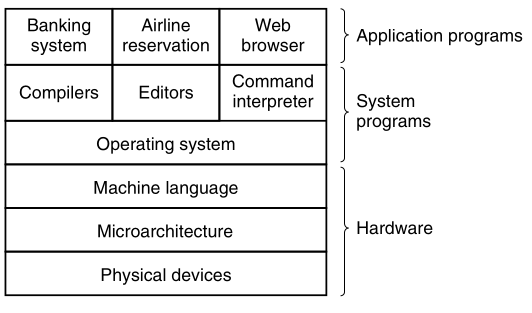
Computer software can be divided roughly into two kinds:
System programs and application programs.
System programs manage the operation of the computer itself.
Application programs perform the actual work the user wants.
The most fundamental system program is the operating
system.
The OS controls all the computer’s resources.
It provide a base,
upon which other system and application programs can be written.
Computers include one or more processors, main memory, disks, printers, a keyboard, a display, network interfaces, and other input/output (I/O) devices.
If every programmer had to be concerned with how disk drives
work,
and with all the dozens of things that could go wrong when reading a
disk block,
it is unlikely that many programs could be written at all.
We put a layer of software on top of the bare hardware,
to efficiently manage all parts of the system.
It presents the user with an interface, or virtual machine,
that is easier to understand and program.
This layer of software is the operating system.
At the bottom is the hardware.
Hardware itself can be composed of two or more levels (or layers).
This lowest level contains physical devices,
consisting of integrated circuit chips, wires, power supplies, cathode
ray tubes,
and similar physical devices.
https://en.wikipedia.org/wiki/Microarchitecture
Next comes the microarchitecture level,
in which the physical devices are grouped together to form functional
units.
Typically this level contains some registers internal to the CPU
(Central Processing Unit),
and a data path containing an arithmetic logic unit.
In each clock cycle, one or two operands are fetched from the
registers,
and combined in the arithmetic logic unit (for example, by addition or
Boolean AND).
The result is stored in one or more registers.
On some machines, the operation of the data path is controlled by
software, called the microprogram.
On other machines, it is controlled directly by hardware circuits.
The purpose of the data path is to execute some set of
instructions.
Some of these can be carried out in one data path cycle;
others may require multiple data path cycles.
These instructions may use registers or other hardware facilities.
Together, the hardware and instructions visible to an assembly
language programmer,
form the ISA (Instruction Set Architecture):
https://en.wikipedia.org/wiki/Instruction_set_architecture
Computer architecture is the combination of microarchitecture and
instruction set architecture:
https://en.wikipedia.org/wiki/Computer_architecture
https://en.wikipedia.org/wiki/Machine_code
A machine language typically has between 50 and 300
instructions.
Instructions move data around the machine, do arithmetic, and compare
values.
Input/Output devices are controlled by loading values into device
registers.
For example,
a disk can be commanded to read,
by loading the values of:
the disk address, main memory address, byte count, and direction (read
or write),
into its registers.
In real practice, many more parameters are needed,
and the status returned by the drive after an operation may be
complex.
A major function of the operating system is to hide lower-level
complexity.
It gives the programmer a more convenient set of instructions to work
with.
For example,
“read block from file” is conceptually much simpler,
than having to worry about the details of moving disk heads,
waiting for them to settle down, and so on.
On top of the operating system is the rest of the system
software.
Here we find the command interpreter (shell).
The shell launches other programs, such as:
window systems, compilers, editors, and application-independent
programs.
These programs are not defined as being part of the kernel of the
operating system.
However, they are often preinstalled by the computer manufacturer,
or in a software package with the operating system itself.
We define the operating system as:
the portion of software that runs in kernel mode or supervisor
mode.
It is usually protected from user tampering by specific hardware
features.
Some older or low-end microprocessors do not have hardware
protection.
Compilers and editors run in user mode.
If a user does not like a particular compiler,
that user may write and use their own.
A programmer in user-mode is not free to re-write the clock interrupt
handler,
which is part of the operating system,
and is normally protected by hardware,
against attempts by users to modify it.
This distinction, however, is sometimes blurred in embedded
systems,
which may not have kernel mode.
The operating system is what runs in kernel mode:
In many systems, there are programs that run in user mode,
but which help the operating system or perform privileged functions.
For example,
there is often a program that allows users to change their
passwords.
For example, on Linux:
/usr/bin/passwd
This program is not part of the operating system,
and does not run in kernel mode,
but it clearly carries out a sensitive function,
and has to be protected in a special way.
In some systems, including MINIX3,
this idea is carried to an extreme form,
and pieces of what is traditionally considered to be the operating
system,
such as the file system, run in user space.
In such systems, it is difficult to draw a clear boundary.
Everything running in kernel mode is clearly part of the operating
system,
but some programs running outside it,
are arguably also part of the core operating system,
or at least closely associated with it.
For example, in MINIX3,
the file system is simply a big C program running in user-mode.
Finally, above the system programs come the application
programs.
These programs are purchased (or written by) the users,
to solve their problems, such as:
word processing, spreadsheets, engineering calculations, storing
information in a database, etc.
https://en.wikipedia.org/wiki/Operating_system
https://en.wikipedia.org/wiki/Kernel_(operating_system)
Operating systems perform two primary functions:
The architecture of most computers at the machine language level
is:
the instruction set, memory organization, I/O, and bus structure.
It is primitive and awkward to program, especially for input/output.
To make this point more concrete,
let us briefly look at how disk I/O is done,
using an NEC PD765 compatible controller chips used on many Intel-based
personal computers.
The PD765 has 16 commands, each specified by loading between 1 and 9
bytes into a device register.
These commands are for:
reading and writing data, moving the disk arm, and formatting
tracks,
as well as initializing, sensing, resetting, and re-calibrating the
controller and the drives.
Read and write example:
The most basic commands are read and write,
each of which requires 13 parameters, packed into 9 bytes.
These parameters specify such items as the address of the disk block to
be read,
the number of sectors per track, the recording mode used on the physical
medium,
the inter-sector gap spacing, and what to do with a
deleted-data-address-mark.
When the operation is completed,
the controller chip returns 23 status and error fields packed into 7
bytes.
If the motor is off, it must be turned on,
(with a long startup delay) before data can be read or written.
The motor cannot be left on too long, however, or the floppy disk will
wear out.
The programmer is thus forced to deal with trade-offs,
between long startup delays versus wearing out floppy disks,
and losing the data on them.
The programmer wants a simple, high-level abstraction to deal with.
For disks, a typical abstraction would be that the disk contains a collection of named files.
Each file can be:
opened for reading or writing,
then read or written,
and finally closed.
The program that hides the messy truth about the hardware from the
programmer,
and presents a nice, simple view of named files,
that can be read and written, is the operating system!
Just as the operating system shields the programmer from the disk
hardware,
and presents a simple file-oriented interface,
it also conceals a lot of unpleasant business,
concerning interrupts, timers, memory management, and other low-level
features.
In each case, the abstraction offered by the operating system,
is simpler and easier to use than that offered by the underlying
hardware.
In this view, one function of the operating system,
is to present the user with the equivalent of an extended machine or
virtual machine,
that is easier to program than the underlying hardware.
The operating system provides a variety of services,
that programs can obtain using special instructions called system
calls.
The operating system provides users with a convenient
interface.
That is a top-down view.
An alternative view is bottom-up:
The operating system can manage all the pieces of a complex
system.
Modern computers consist of:
processors, memories, timers, disks, mice, network interfaces,
printers,
and a wide variety of other devices.
One job of the operating system is to provide for an orderly and
controlled allocation,
of the processors, memories, and I/O devices,
among the various programs (processes) competing for them.
When a computer (or network) has multiple users,
the need for managing and protecting the resources,
memory, I/O devices, is even greater,
since the users might otherwise interfere with one another.
In addition to hardware,
users also share information like files, databases, etc.
The operating system keeps track of who is using which
resource,
to grant resource requests, to account for usage,
and to mediate conflicting requests from different programs and
users.
Resource management includes multiplexing (sharing) resources in two
ways:
in time, and
in space.
https://en.wikipedia.org/wiki/Scheduling_(computing)
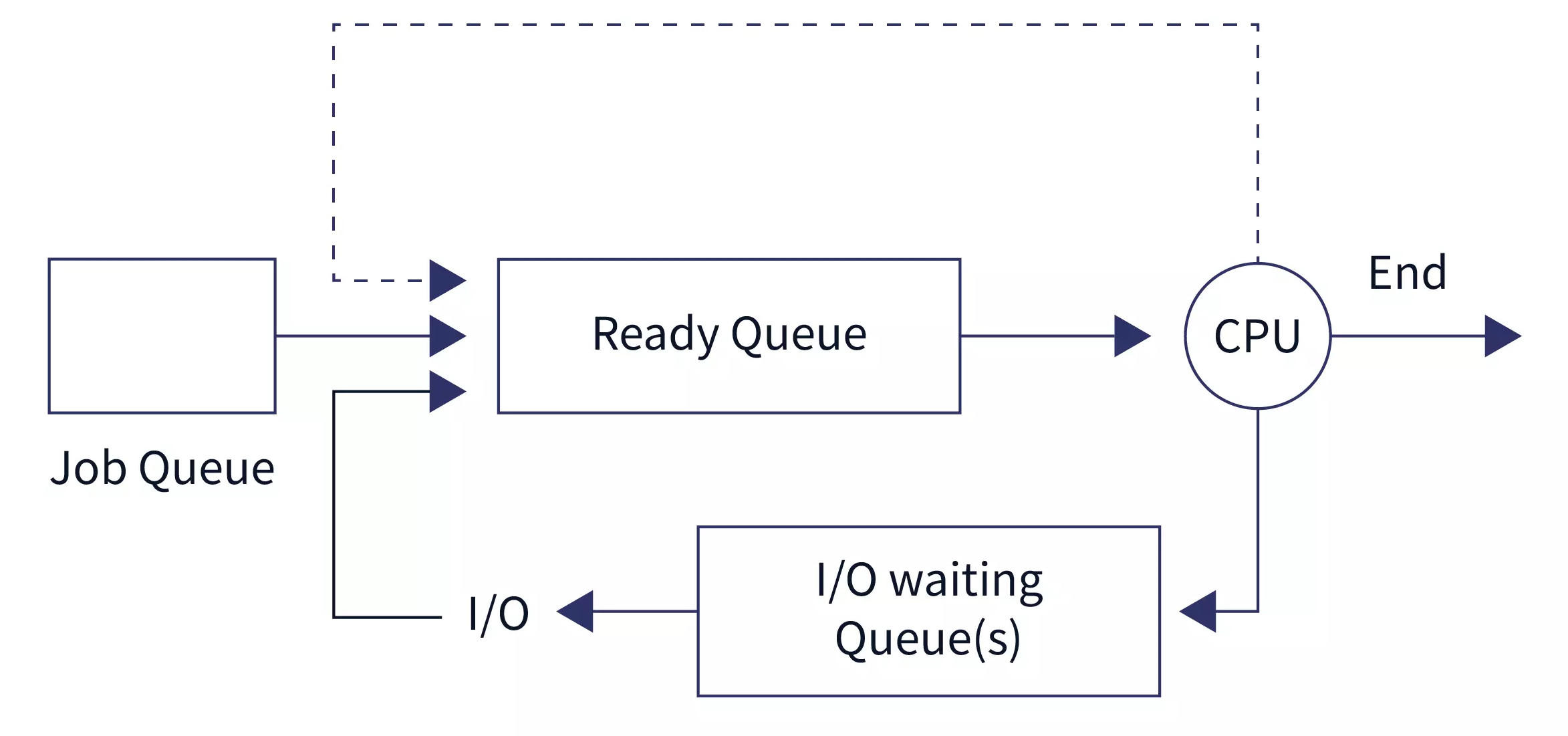
When a resource is time-multiplexed,
different programs, or users, take turns using it.
First, one of them gets to use the resource,
then another, and so on.
For example, with only one CPU and multiple programs that want to run
on it,
the operating system first allocates the CPU to one program,
then after it has run long enough,
another one gets to use the CPU, then another,
and then eventually the first one again.
Determining how the resource is time multiplexed,
who goes next and for how long,
is the task of the operating system’s scheduler.
The other kind of multiplexing is space multiplexing.
For example,
main memory is normally divided up among several running programs,
so each one can be resident at the same time.
For example, to take turns using the CPU.
Assuming there is enough memory to hold multiple programs,
it is more efficient to hold several programs in memory at once,
rather than give one of them all of it,
especially if it only needs a small fraction of the total.
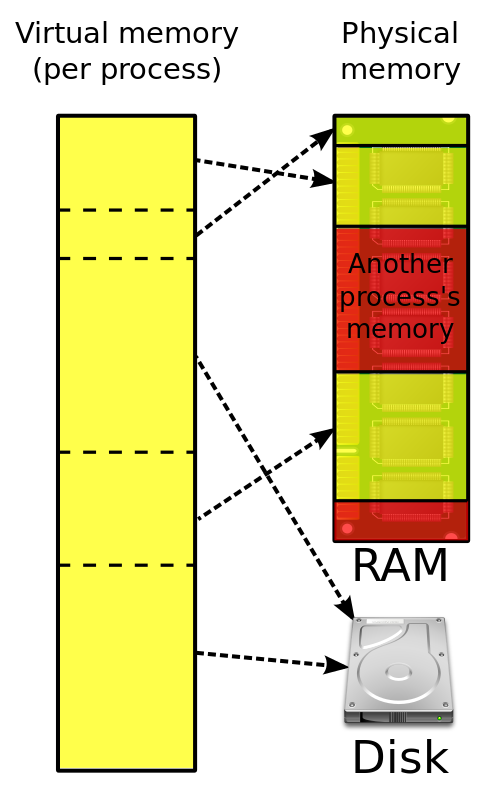
Potential issues that arise include fairness and protection.
Operating system designers can address these issues.
Another resource that is space multiplexed is the (hard) disk.
In many systems a single disk can hold files from many users at the same
time.
Allocating disk space, and keeping track of who is using which disk
blocks,
is a typical operating system resource management task.
++++++++++++
Cahoot-01-01
The interface between the operating system and the user
programs,
is defined by the set of “extended instructions” that the operating
system provides.
These extended instructions have been traditionally known as
system calls,
although they can be implemented in several ways.
To really understand what operating systems
do,
we must examine the system call interface closely!
The calls available in the interface vary from operating system to
operating system.
Although, the underlying concepts tend to be similar.
We are thus forced to make a choice between:
(1) vague generalities
(“operating systems have system calls for reading files”) and
(2) some specific system
“MINIX3 has a read system call with three parameters:
one to specify the file,
one to tell where the data are to be put,
and one to tell how many bytes to read”.
https://en.wikipedia.org/wiki/System_call
We will look closely at the basic system calls present in UNIX
(including the various versions of BSD), Linux, and MINIX3.
The MINIX3 system calls fall roughly in two broad categories:
Treating everything as a file,
allows these two categories of system call to operate broadly.
For example, on my x86-64bit Linux:
https://en.wikipedia.org/wiki/Process_(computing)
A key concept in MINIX3, and in all operating systems, is the
process.
A process is basically an instance of a program in execution,
with it’s associated housekeeping data,
all the other information needed to run the program.
Associated with each process is its address space in memory.
A process can read and write to memory in list of locations,
from some minimum (usually 0) to some maximum.
The address space also contains:
the executable program instructions,
the program’s data, and
its stack.
Also associated with each process is some set of registers and their
values.
Some common registers include:
the program counter, stack pointer, and other hardware registers.
In multi-programming systems,
periodically, the operating system decides to stop running one
process,
and start running another.
For example, the first one may have had more than its share of CPU time
in the past second.
When a process is suspended temporarily like this,
it must later be restarted,
in exactly the same state it had when it was stopped.
Thus, All information about the process must be saved, before the
suspension.
For example, the process may have several files open for reading at
once.
Associated with each of these files is a pointer to the current
position
(i.e., the number of the byte or record to be read next).
All these pointers must be saved,
so that a read call executed after the process is restarted,
will read the proper data.
In many operating systems, all the information about each
process,
other than the contents of its own address space,
is stored in an operating system table,
called the process table.
The table is an array (or linked list) of structures,
one for each process currently in existence.
A (suspended) process consists of its address space,
usually called the core image,
and its process table entry,
which contains its register values, among other things.
Process management system calls deal with the creation and termination of processes.
Consider a typical example:
A common process is the command interpreter, or shell,
It reads commands from a terminal and executes them.
The user may have just typed a command requesting that a program be
compiled.
The shell must now create a new process that will run the
compiler.
When that called process has finished the compilation,
it executes a system call to terminate itself.
Other process-related system calls include those that:
request more memory (or release unused memory),
wait for a child process to terminate, or
overlay its program with a different one.
A process can create one or more other processes,
usually referred to as child processes.
These processes, in turn, can create child processes.
This creates a process tree structure:
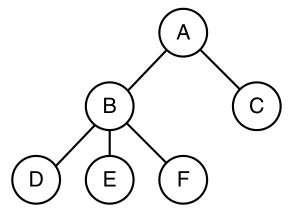
Process A created two child processes, B and C.
Process B created three child processes, D, E, and F.
https://en.wikipedia.org/wiki/Inter-process_communication
Related processes that are cooperating to get some job done,
often need to communicate with one another,
and synchronize their activities.
This communication is called inter-process communication (IPC).
https://en.wikipedia.org/wiki/Signal_(IPC)
On the other hand,
a running process may not immediately expect input,
but there is often a need to convey information to a that running
process anyway.
Signals are standardized messages sent to a running program,
to trigger specific behavior, such as quitting or error handling.
For example, a process that is communicating with another process on
a different computer,
does so by sending messages to the remote process over a network.
To guard against the possibility that a message or its reply is
lost,
the sender may request that its own operating system notify it,
after a specified number of seconds,
so that it can re-transmit the message,
if no acknowledgment has been received yet.
After setting this timer, the program may continue doing other
work.
When the specified number of seconds has elapsed,
the operating system sends an alarm signal to the process.
The signal causes the process to temporarily suspend whatever it was
doing,
save its registers on the stack,
and start running a special signal handling procedure,
for example, to re-transmit a presumably lost message.
When the signal handler is done,
the running process is restarted in the state it was in just before the
signal.
https://en.wikipedia.org/wiki/Interrupt
Signals are the software analog of hardware interrupts.
They are generated by a variety of causes.
Many traps detected by hardware,
such as executing an illegal instruction,
or using an invalid address,
are also converted into signals to the guilty process.
Each person authorized to use a MINIX3 system,
is assigned a UID (User IDentification) by the system
administrator.
Every process started has the UID of the person who started it.
A child process has the same UID as its parent.
One UID, called the superuser (in UNIX),
has special power and may violate many of the protection rules.
Further, users can be members of groups,
each of which has a GID (Group IDentification).
Permissions for to operate on files acan be issues to UIDs or
GIDs,
which are inherited by processes launched by users or groups.
https://en.wikipedia.org/wiki/Computer_file
https://en.wikipedia.org/wiki/File_system
The other broad category of system calls relates to the file
system.
The operating system hides details of the disks and other I/O
devices,
and presents the programmer with an abstract model of device-independent
files.
System calls create files, remove files, read files, and write
files.
Before a file can be read,
it must be opened.
After a file has been read,
it should be closed.
System calls are provided to do these things.
https://en.wikipedia.org/wiki/Directory_(computing)/
To provide a place to keep and organize files,
MINIX3 has the concept of a directory,
as a way of grouping files together.
Directory entries may be either files or other directories.
This model also gives rise to a hierarchy.
For example, a file system for a university department:
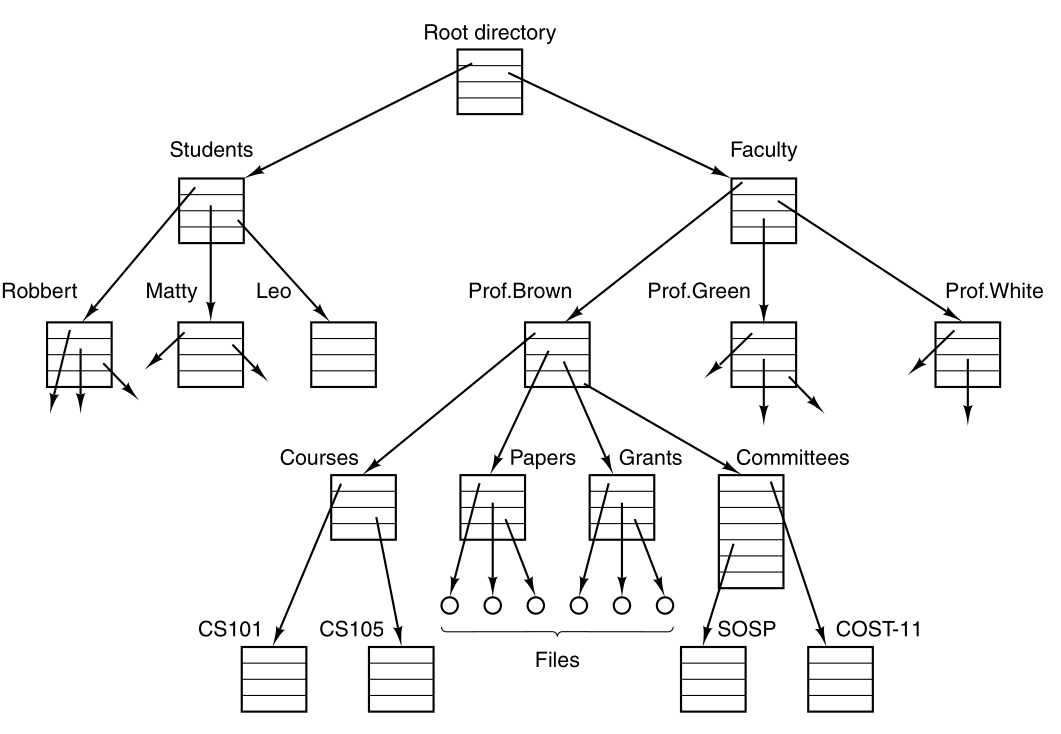
Every file within the directory hierarchy can be specified,
by giving its path name from the top of the directory hierarchy,
the root directory, for example:
/Faculty/Prof.Brown/Courses/CS101
Such absolute path names consist of the list of directories,
that must be traversed from the root directory (/),
to get to the file,
with slashes separating the components.
Calls create and remove directories.
Calls also put an existing file into a directory,
and remove a file from a directory.
Process and file hierarchies are both organized as trees,
but the similarity stops there.
Process hierarchies usually are not very deep
(more than three levels is unusual).
File hierarchies are commonly four, five, or even more levels deep.
Process hierarchies are typically short-lived,
generally a few minutes at most,
Directory hierarchies may exist for years.
Ownership and protection also differ for processes and files.
Typically, only a parent process may control or even access a child
process.
But, a wider group than just the owner,
may be permitted to access files and directories.
https://en.wikipedia.org/wiki/Working_directory
Each process always has a current working directory,
in which path names not beginning with a slash are looked for.
Processes can change their working directory,
by issuing a system call specifying the new working directory.
https://en.wikipedia.org/wiki/File-system_permissions
../../Security/Content/19b-Permissions.html
Files and directories in MINIX3 are protected,
by assigning each one an 11-bit binary protection code.
The protection code consists of three 3-bit fields:
one for the owner,
one for other members of the owner’s group
(users are divided into groups by the system administrator),
one for everyone else (other),
and 2 bits we will discuss later.
Each field has a bit for:
read access, r,
write access, w,
execute access, x.
These 3 bits are known as the rwx bits.
Dash - means that the corresponding permission is absent
(the bit is zero).
For example, the protection code:
rwx r-x --x
means that the:
owner can read, write, or execute the file,
other group members can read or execute (but not write)
the file,
and everyone else can execute (but not read or write)
the file.
For a directory (as opposed to a file),
x indicates search permission.
Before a file can be read or written,
it must be opened,
at which time the permissions are checked.
If access is permitted,
the system returns a small integer called a file descriptor,
to use in subsequent operations.
If the access is prohibited,
an error code (-1) is returned.
MINIX3 can also mount file systems.
To deal with removable media (CD-ROMs, DVDs, floppies, Zip drives, USB
disks, etc.),
MINIX3 allows the file system on an external disk to be attached to the
main tree.
Consider the situation below:
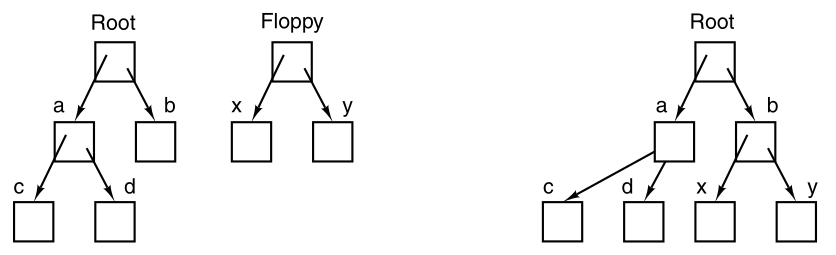
Left: Before mounting, the files on floppy drive are not
accessible.
Right: After mounting, they are part of the file hierarchy.
Before the mount call, the root file system, on the hard disk,
and a second file system, on an external disk,
are separate and unrelated.
The file system on drive 0 has been mounted on directory b,
thus allowing access to files /b/x and /b/y.
MINIX3 does not allow path names to be prefixed by a drive name or
number;
that is the kind of device dependence that operating systems ought to
eliminate.
Instead, the mount system call allows the file system on the external
drive,
to be attached to the root file system,
wherever the program wants it to be.
Another important concept in MINIX3 is the special file.
Special files make I/O devices look like files.
They can be read and written,
using the same system calls as are used for reading and writing
files.
Two kinds of special files exist:
By convention, the special files are kept in the /dev
directory.
For example, /dev/lp might be the line printer.
Block special files are normally used to model
devices,
that consist of a collection of randomly addressable blocks, such as
disks.
By opening a block special file and reading, say, block 4,
a program can directly access the fourth block on the device,
without regard to the structure of the file system contained on it.
Similarly, character special files are used to model:
printers, modems, and other devices that accept or output a character
stream.
These special files allow re-using system calls for processes and filesystems!
https://en.wikipedia.org/wiki/Pipeline_(Unix)
One feature applies to both processes and files:
A pipe is a sort of pseudo-file,
that can be used to connect two processes, as shown:
Two processes connected by a pipe:
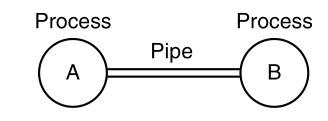
If processes A and B wish to talk using a pipe,
then they must set it up in advance.
When process A wants to send data to process B,
it writes on the pipe as though it were an output file.
Process B can read the data,
by reading from the pipe,
as though it were an input file.
Communication between processes in MINIX3,
looks very much like ordinary file reads and writes.
A process does not know the output process it is writing on,
that it is not really a file, but a pipe.
A process could discover this fact by making a special system call.
Again, we re-use mechanisms for reading and writing files!
https://en.wikipedia.org/wiki/Shell_(computing)
Reminder:
The operating system is the code that carries out the system calls.
Editors, compilers, assemblers, linkers, and command
interpreters,
are not part of the operating system,
even though they are important and useful.
The MINIX3 command interpreter is called the shell.
Although it is not part of the kernel of the operating system,
it makes heavy use of many operating system features,
and thus serves as a good example of how the system calls can be
used.
The shell is also the primary interface between a user sitting at a
terminal,
and the operating system.
Many shells exist, including: csh, ksh,
zsh, bash, fish, etc.
All of them support the functionality described below,
which derives from the original shell (sh).
When any user logs in, a shell is started up.
By default,
the shell uses command line terminal itself as standard input and
standard output.
The shell starts out by typing the prompt to the
screen.
The prompt is a character such as a dollar sign:
$
which tells the user that the shell is waiting to accept a command from
the keyboard.
If the user now types
date
for example, the shell creates a child process,
and runs the date program as the child.
While the child process is running,
the shell waits for it to terminate.
When the child finishes,
the shell types the prompt again,
and waits for the next input line to be typed and entered.
https://en.wikipedia.org/wiki/Redirection_(computing)
The user can specify that standard output be redirected to a
file,
for example:
date >file
Similarly, standard input can be redirected,
as in:
sort <file1
which invokes the sort program,
with input taken from file1.
Or both:
sort <file1 >file2
which invokes the sort program,
with input taken from file1,
and output sent to file2.
The shell can use the OS-provided feature of:
https://en.wikipedia.org/wiki/Pipeline_(Unix)
The output of one program,
can be used as the input for another program,
by connecting them with a pipe.
cat file1 file2 file3 | sort >/dev/lp
invokes the cat program,
to concatenate three files,
and send the output to sort,
to arrange all the lines in alphabetical order.
The output of sort is redirected,
to the file /dev/lp,
typically the printer.
If a user puts an ampersand (&) after a
command,
then the shell runs it in the background,
and does not wait for it to complete,
before displaying the prompt again.
cat file1 file2 file3 | sort >/dev/lp &
starts up the sort as a background job,
allowing the user to continue working normally,
while the sort is going on.
https://en.wikipedia.org/wiki/Kernel_(operating_system)#Kernel-wide_design_approaches
Now that we have vaguely seen what operating systems look like on the
outside,
i.e, the programmer’s interface,
it is time to take a look inside.
Some example OS designs include:
monolithic systems,
layered systems,
virtual machines,
exokernels,
client-server systems,
microkernels,
distributed systems
There are many more!
https://en.wikipedia.org/wiki/Monolithic_kernel
By far the most common organization,
this approach might well be subtitled “The Big Mess.”
The structure is that there is no structure.
The operating system is written as a collection of procedures,
each of which can call any of the other ones whenever it needs to.
Each procedure in the system has a well-defined interface,
in terms of parameters and results,
and each one is free to call any other one,
if the latter provides some useful computation that the former
needs.
To construct the actual object program of the operating system,
when this approach is used,
one first compiles all the individual procedures,
or files containing the procedures,
and then binds them all together,
into a single object file using the system linker.
In terms of information hiding,
there is essentially none.
Every procedure is visible to every other procedure,
as opposed to a structure containing modules or packages,
in which much of the information is hidden away inside modules,
and only the officially designated entry points,
can be called from outside the module.
Even in monolithic systems,
it is possible to have at least a little structure.
The services (system calls) provided by the operating system,
are requested by putting the parameters in well-defined places,
such as in registers or on the stack,
and then executing a special trap instruction,
known as a kernel call or supervisor call.
This instruction switches the machine from user mode to kernel
mode,
and transfers control to the operating system.
Most physical CPUs have two modes:
kernel mode, for the operating system,
in which all instructions are allowed; and
user mode, for user programs,
in which I/O and certain other instructions are not allowed.
Recall that the read call is used like this:
count = read(fd, buffer, nbytes);
In preparation for calling the read library procedure,
which actually makes the read system call,
the calling program first pushes the parameters onto the stack,
as shown:
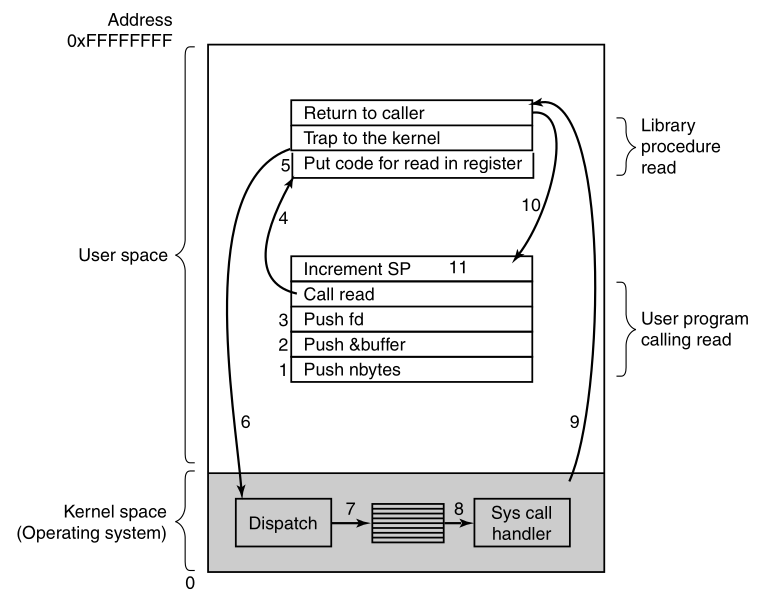
The 11 steps in making the system call
read(fd, buffer, nbytes).
C and C++ compilers push the parameters onto the stack in reverse
order.
The first and third parameters are called by value,
but the second parameter is passed by reference,
meaning that the address of the buffer (indicated by &) is
passed,
not the contents of the buffer.
Then comes the actual call to the library procedure (step 4).
This instruction is the normal procedure call instruction,
used to call all procedures.
The library procedure, possibly written in assembly language,
typically puts the system call number in a place where the operating
system expects it,
such as a register (step 5).
Then it executes a TRAP instruction,
to switch from user mode to kernel mode,
and start execution at a fixed address within the kernel (step 6).
The kernel code that starts,
examines the system call number,
and then dispatches to the correct system call handler,
usually via a table of pointers to system call handlers,
indexed on system call number (step 7).
At that point, the system call handler runs (step 8).
Once the system call handler has completed its work,
control may be returned to the user-space library procedure,
at the instruction following the TRAP instruction (step 9).
This procedure then returns to the user program,
in the usual way procedure calls return (step 10).
To finish the job, the user program has to clean up the stack,
as it does after any procedure call (step 11).
Assuming the stack grows downward, as it often does,
the compiled code increments the stack pointer,
exactly enough to remove the parameters pushed before the call to
read.
The program is now free to do whatever it wants to do next.
In step 9 above, we said:
“may be returned to the user-space library procedure”
for good reason.
The system call may block the caller,
preventing it from continuing.
For example, if it is trying to read from the keyboard,
and nothing has been typed yet,
the caller has to be “blocked.”
In this case, the operating system will look around,
to see if some other process can be run next.
Later, when the desired input is available,
this process will get the attention of the system,
and steps 9-11 will occur.
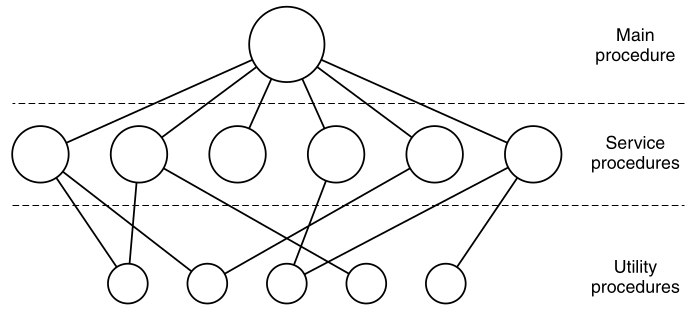
This organization suggests a basic structure for the operating system:
In this model, for each system call,
there is one service procedure that takes care of it.
The utility procedures do things that are needed by several service
procedures,
such as fetching data from user programs.
This division of the procedures into three layers is shown:
A simple structuring model for a monolithic system.
What goes in the modern Linux kernel?
https://makelinux.github.io/kernel/map/
https://makelinux.github.io/kernel/diagram/
https://news.ycombinator.com/item?id=37490623
A generalization of the approach above,
is to organize the operating system as a hierarchy of layers,
each one constructed upon the one below it.
The first system constructed in this way was the “THE system”,
built at the Technische Hogeschool
Eindhoven in the Netherlands,
by E. W. Dijkstra and his students.
The THE system was a simple batch system for a Dutch computer,
the Electrologica X8, which had 32K of 27-bit words
(bits were expensive back then).
The system had 6 layers, as shown:

Structure of the THE operating system.
dealt with allocation of the processor,
switching between processes when interrupts occurred or timers
expired.
Above layer 0, the system consisted of sequential processes,
each of which could be programmed,
without having to worry about multiple processes running on a single
processor.
Layer 0 provided the basic multi-programming of the CPU.
did the memory management.
It allocated space for processes in main memory,
and on a 512K word drum,
used for holding parts of processes (pages),
for which there was no room in main memory.
Above layer 1, processes did not have to worry about whether they were
in memory or on the drum;
the layer 1 software took care of making sure pages were brought into
memory whenever they were needed.
handled communication between each process,
and the operator console.
Above this layer each process effectively had its own operator
console.
took care of managing the I/O devices,
and buffering the information streams to and from them.
Above layer 3 each process could deal with abstract I/O devices,
instead of real devices with many peculiarities.
was where the user programs were found.
They did not have to worry about process, memory, console, or I/O
management.
The system operator process was located in layer 5.
A further generalization of the layering concept was present in the MULTICS system.
Instead of layers, MULTICS was organized as a series of concentric
rings,
with the inner ones being more privileged than the outer ones.
When a procedure in an outer ring wanted to call a procedure in an inner
ring,
it had to make the equivalent of a system call, that is,
a TRAP instruction whose parameters were carefully checked for
validity,
before allowing the call to proceed.
Although the entire operating system was part of the address space of
each user process in MULTICS,
the hardware made it possible to designate individual procedures (memory
segments, actually),
as protected against reading, writing, or executing.
The THE layering scheme was really only a design aid,
because all the parts of the system were ultimately linked
together,
into a single object program.
In MULTICS,
the ring mechanism was very much present at run time,
and enforced by the hardware.
The advantage of the ring mechanism,
is that it can easily be extended to structure user subsystems.
For example,
a professor could write a program to test and grade student
programs,
and run this program in ring n,
with the student programs running in ring n + 1,
so that they could not change their grades.
https://en.wikipedia.org/wiki/Virtual_machine
https://en.wikipedia.org/wiki/System_virtual_machine
Multiple virtual machines on one physical machine.
A group at IBM’s Scientific Center in Cambridge, Massachusetts,
produced a radically different system.
This system, originally called CP/CMS, and later renamed VM/370,
was based on a very astute observation.
A time-sharing system provides both:
The essence of VM/370 is to completely separate these two functions.
The heart of the system,
known as the virtual machine monitor,
runs on the bare hardware and does the multi-programming.
The next layer provides not one, but several virtual machines,
to the next layer up, as shown:
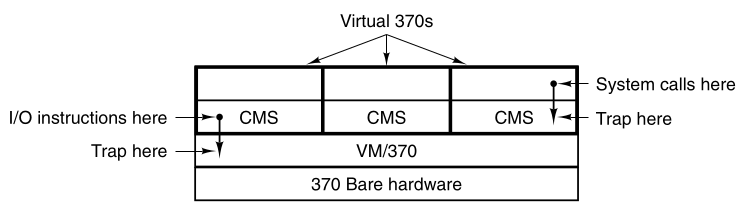
The structure of VM/370 with CMS.
However, unlike other operating systems that existed,
these virtual machines are not extended machines,
with files and other nice features.
Instead, they were exact copies of the bare hardware,
including kernel/user mode, I/O, interrupts,
and everything else the real machine has.
Because each virtual machine is identical to the true hardware,
each one can run any operating system,
that will run directly on the bare hardware.
Different virtual machines can, and frequently do, run different
operating systems.
Some ran one of the descendants of OS/360 for batch or transaction
processing,
while others ran a single-user, interactive system,
called CMS (Conversational Monitor System) for time-sharing users.
When a CMS program executes a system call,
the call is trapped to the operating system,
in its own virtual machine, not to VM/370,
just as it would if it were running on a real machine,
instead of a virtual one.
CMS then issues normal hardware I/O instructions for reading its virtual
disk,
or whatever is needed to carry out the call.
These I/O instructions are trapped by VM/370,
which then performs them as part of its simulation of the real
hardware.
With the VM/370 system, it is possible to run VM/370,
itself, in the virtual machine…
With VM/370, each user process gets an exact copy of the actual
computer.
By making a complete separation of the functions of
multi-programming,
and providing an extended machine,
each of the pieces can be much simpler, more flexible, and easier to
maintain.
https://en.wikipedia.org/wiki/Hypervisor
Some OS’s are intended to be virtual guests,
and thus support efficiency improvements:
https://en.wikipedia.org/wiki/Paravirtualization
In this case, they don’t use the normal (pseudo) IO mechanisms,
but the guest operating system to make a system call to the underlying
hypervisor,
rather than executing machine I/O instructions that the hypervisor
simulates.
https://en.wikipedia.org/wiki/Exokernel
Going one step further, researchers at M.I.T. built a new
system,
that gives each user a clone of the actual computer,
but with a subset of the resources.
Thus one virtual machine might get disk blocks 0 to 1023,
the next one might get blocks 1024 to 2047, and so on.
At the bottom layer, running in kernel mode, is a program called the
exokernel.
Its job is to allocate resources to virtual machines,
and then check attempts to use them,
to make sure no machine is trying to use somebody else’s resources.
Each user-level virtual machine can run its own operating
system,
as on VM/370 and the Pentium virtual 8086s,
except that each one is restricted,
to using only the resources it has asked for and been allocated.
The advantage of the exokernel scheme is that it saves a layer of
mapping.
In the other designs, each virtual machine thinks it has its own
disk,
with blocks running from 0 to some maximum,
so the virtual machine monitor must maintain tables,
to remap disk addresses (and all other resources).
With the exokernel, this remapping is not needed.
The exokernel need only keep track of which virtual machine has been
assigned which resource.
This method still has the advantage of separating:
the multi-programming (in the exokernel),
from the user operating system code (in user space),
but with less overhead,
since all the exokernel has to do,
is keep the virtual machines out of each other’s hair.
since functionality is limited to ensuring protection and
multiplexing of resources,
which is considerably simpler than conventional microkernels’
implementation of message passing,
and monolithic kernels’ implementation of high-level abstractions.
VM/370 gained much in simplicity,
by moving a large part of the traditional operating system code
(implementing the extended machine) into a higher layer.
One goal is to move more code up into higher layers,
and remove as much as possible from the operating system,
leaving a minimal kernel.
That approach implements most of the operating system functions in user
processes.
To request a service,
such as reading a block of a file,
a user process (now known as the client process)
sends the request to a server process,
which then does the work and sends back the answer.
In this model, shown here:
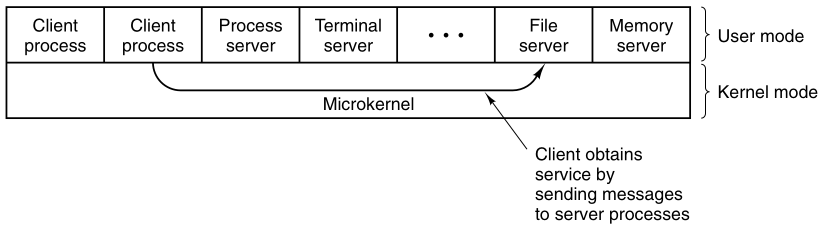
All the kernel does is handle the communication between clients and
servers.
By splitting the operating system up into parts,
each of which only handles one facet of the system,
such as file service, process service, terminal service, or memory
service,
each part becomes small and manageable.
All the servers run as user-mode processes,
and not in kernel mode.
Thus, they do not have direct access to the hardware.
If a bug in the file server is triggered,
the file service may crash,
but this will not usually bring the whole machine down.
https://en.wikipedia.org/wiki/Microkernel
Also provides the near-minimum amount of OS software.
These mechanisms include:
low-level address space management,
thread management, and
inter-process communication (IPC).
As a microkernel must allow building arbitrary operating system
services on top,
it must provide some core functionality.
At a minimum, this includes:
Some mechanisms for dealing with address spaces,
required for managing memory protection.
Some execution abstraction to manage CPU allocation,
typically threads or scheduler activations.
Inter-process communication is required,
to invoke servers running in their own address spaces.
https://en.wikipedia.org/wiki/Distributed_computing
https://en.wikipedia.org/wiki/Multikernel
Another advantage of the client-server model is its adaptability to use
in distributed systems:
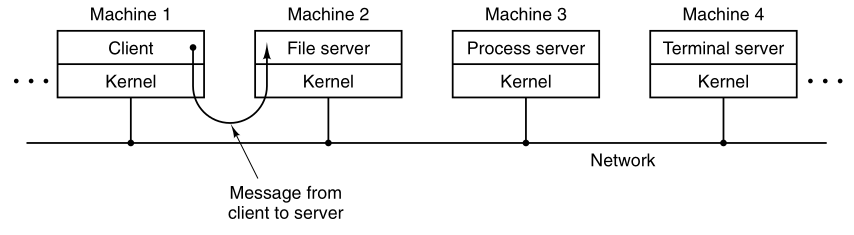
The client-server model in a distributed system.
If a client communicates with a server by sending it messages,
then the client need not know whether the message is handled locally in
its own machine,
or whether it was sent across a network to a server on a remote
machine.
As far as the client is concerned,
the same thing happens in both cases:
a request was sent and a reply came back.
The picture painted above of a kernel that handles only the transport
of messages,
from clients to servers and back is not completely realistic.
Some operating system functions,
such as loading commands into the physical I/O device registers,
are difficult, if not impossible, to do from user-space programs.
There are two ways of dealing with this problem:
The first way is to have some critical server processes (e.g., I/O
device drivers)
actually run in kernel mode, with complete access to all the
hardware,
but still communicate with other processes using the normal message
mechanism.
A variant of this mechanism was used in earlier versions of
MINIX,
where drivers were compiled into the kernel but ran as separate
processes.
The second way is to build a minimal amount of mechanism into the
kernel,
but leave the policy decisions up to servers in user space.
For example,
the kernel might recognize that a message sent to a certain special
address,
means to take the contents of that message,
and load it into the I/O device registers for some disk,
to start a disk read.
The kernel would not even inspect the bytes in the message,
to see if they were valid or meaningful;
it would just blindly copy them into the disk’s device registers.
For security, some scheme for limiting such messages to authorized processes only must be used.
This is how MINIX3 works.
Drivers are in user space.
But, they use special kernel calls,
to request reads and writes of I/O registers,
or to access kernel information.
The split between mechanism and policy is an important concept;
it occurs again and again in operating systems in various contexts.
https://en.wikipedia.org/wiki/Comparison_of_operating_system_kernels
https://en.wikipedia.org/wiki/Comparison_of_operating_systems
Operating systems can be viewed from two viewpoints:
resource managers and extended machines.
In the resource manager view,
the operating system’s job is to efficiently manage the different parts
of the system.
In the extended machine view,
the job of the system is to provide the users with a virtual
machine,
that is more convenient to use than the actual machine.
Operating systems can be structured in several ways.
Some common ones are as a:
monolithic system, hierarchy of layers,
virtual machine system,
using an exokernel, and
using the client-server model,
enabling microkernels and distributed systems..
Operating systems typically have four major components:
process management,
I/O device management,
memory management, and
file management.
+++++++++++++++++++
Discussion question:
Can you think of any reasons why there is so little diversity in OS
usage, and why most major operating systems are monolithic?
These could be either technical, or non-technical reasons.
The heart of any operating system is the set of system calls
that it can handle.
These tell what the core of the operating system really
does.
For example, on my x86-64bit Linux:
Armed with our general knowledge of how MINIX3 deals with processes
and files,
we can now begin to look at the interface,
between the operating system and its application programs,
that is, the set of system calls.
For MINIX3, these calls can be divided into six groups:
Although this discussion specifically refers to POSIX,
hence also to MINIX3, UNIX , and Linux,
most other modern operating systems have system calls that perform the
same functions,
even if the details differ.
Since the actual mechanics of issuing a system call are highly machine
dependent,
and often must be expressed in assembly code,
a procedure library is provided to make it possible to make system calls
from C programs.
Any single-CPU computer can execute only one instruction at a
time.
If a process is running a user program in user mode,
and needs a system service, such as reading data from a file,
then it has to execute a trap or system call instruction,
to transfer control to the operating system.
By inspecting the parameters.
the operating system then figures out what the calling process
wants.
Then the OS carries out the system call,
and returns data and control to the calling instruction following the
system call.
Making a system call is like making a special kind of procedure
call,
only system calls execute kernel or other privileged operating system
operations,
and procedure calls do not.
To make the system call mechanism clearer,
let us take a quick look at read.
It has three parameters:
the first one specifying the file descriptor,
the second one specifying the buffer, and
the third one specifying the number of bytes to
read.
A call to read from a C program might look like this:
count = read(fd, buffer, nbytes);
The system call (and the library procedure, read) return
the number of bytes actually read,
into the return value, count.
This value is normally the same as nbytes,
but may be smaller, if, for example, an end-of-file is encountered while
reading.
If the system call cannot be carried out,
either due to an invalid parameter, or a disk error,
count is set to -1,
and the error number is put in a global variable,
errno.
Programs should always check the results of a system call to see if an
error occurred.
MINIX3 has a total of 53 main system calls!
These are listed below,
grouped for convenience in six categories.
A few other calls exist,
but they have very specialized uses so we will omit them here.
To a large extent, the services offered by these calls,
determine most of what the operating system has to do.
The resource management on personal computers is minima,
at least compared to big machines with many users.
We will briefly examine each of the calls to see what it does.
This is just an overview.
We’ll do them all in detail later.
The mapping of POSIX procedure calls onto system calls is not
necessarily one-to-one.
The POSIX standard specifies a number of procedures,
that a conformant system must supply,
but it does not specify whether they are system calls, library calls, or
something else.
In some cases, the POSIX procedures are supported as library routines in
MINIX3.
In other cases, several required procedures are only minor variations of
one another,
and one system call handles all of them.
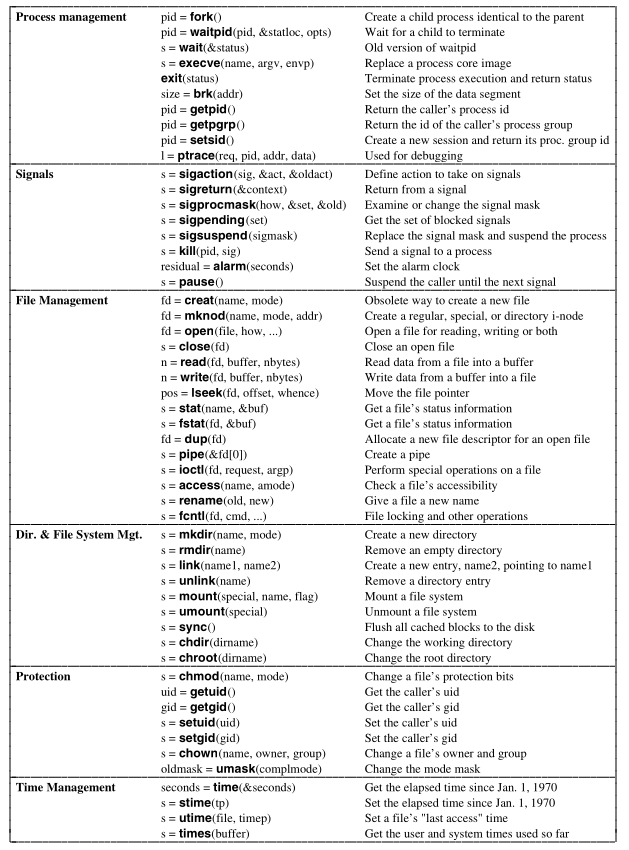
The first group of calls deals with process management.
pid = fork()
is the only way to create a new process in MINIX3.
Duplication:
It creates an exact duplicate of the original process,
including all the file descriptors, registers, and everything
else.
After the fork, the original process (parent) and the copy (child)
diverge.
All the variables have identical values at the time of the fork.
Since the parent’s data are copied to create the child,
subsequent changes in one of them,
do not affect the other one.
The “program text” section in memory, which is unchangeable,
is shared between parent and child.
Process ID:
The fork call returns a value,
which in the child is zero,
and in the parent is equal to the child’s process identifier, or
PID.
Using the returned PID,
the two processes can see which one is the parent process,
and which one is the child process.
Post-fork:
In most cases, after a fork,
the child will need to execute different code from the parent.
Consider the shell.
It reads a command from the terminal,
forks off a child process,
waits for the child to execute the command,
and then when the child terminates,
it reads the next command.
To wait for the child to finish,
the parent executes a waitpid system call:
pid = waitpid(pid, &statloc, opts)
It just waits until the child terminates
(actually any child terminates, if more than one exists).
waitpid can wait for a specific child’s PID,
or for any old child, by setting the first parameter to -1.
When waitpid completes,
the value at the address pointed to by the second parameter,
statloc,
will be set to the child’s exit status.
Status includes:
a normal or abnormal termination, and exit value.
Various options are also provided,
specified by the third parameter, opts.
s = wait(&status)
waitpid replaces the previous wait call,
which is now obsolete,
but is provided for reasons of backward compatibility.
Now consider how fork is used by the shell.
When a command is typed, the shell forks off a new process.
This child process must execute the user command.
It does this by using the execve system call,
which causes its entire core image to be replaced,
by the file named in its first parameter:
s = execve(name, arg, envp)
The system call itself is exec,
but several different library procedures call it,
with different parameters and slightly different names.
We will treat all of these as system calls here.
Below, is a highly simplified shell illustrating the use of:
fork, waitpid, and execve.
#define TRUE 1
/* repeat forever */
while (TRUE) {
/* display prompt on the screen */
type_prompt();
/* read input from terminal */
read_command(command, parameters);
/* fork off child process */
if (fork() != 0) {
/* Parent code.*/
/* wait for child to exit */
waitpid(−1, &status, 0);
} else {
/* Child code./
/* execute command */
execve(command, parameters, 0);
}
}TRUE is assumed to be defined as 1.
In the most general case, execve has three
parameters:
1. the name of the file to be executed,
2. a pointer to the argument array, and
3. a pointer to the environment array.
Specifically:
s = execve(name, arg, envp)
Various library routines are included:
execl, execv, execle, and
execve,
These allow the parameters to be omitted, or specified in various
ways.
We will use the name exec to represent the system call
invoked by all of these.
Let us consider the case of a shell command such as:
cp file1 file2
This copes file1 to file2.
After the shell has forked,
the child process locates and executes the executable file
cp,
and passes to it the names of the source and target files.
As with most C programs,
the main program of cp contains the declaration:
main(argc, argv, envp)
where argc is a count of the number of items on the
command line,
including the program name.
For the example above, argc is 3.
The second parameter, argv, is a pointer to an
array.
Each element i of that array is a pointer,
to the i-th string on the command line.
In our example,
argv[0] would point to the string "cp",
argv[1] would point to the string "file1",
and
argv[2] would point to the string "file2".
The third parameter of main, envp,
is a pointer to the environment,
an array of strings containing assignments of the form name=value,
used to pass information to a program.
Information includes that like the terminal type and home directory
name.
In the code, no environment is passed to the child,
so the third parameter of execve is a zero.
If exec seems complicated, do not despair;
it is (semantically) the most complex of all the POSIX system
calls.
All the others are much simpler.
Consider:
exit(status)
which processes should use when they are finished executing.
It has one parameter,
the exit status (0 to 255),
which is returned to the parent,
via statloc in the waitpid system call.
The low-order byte of status,
contains the termination status,
with 0 being normal termination,
and the other values being various error conditions.
The high-order byte of status,
contains the child’s exit status (0 to 255).
If a parent process executes the statement:
n = waitpid(-1, &statloc, options);
it will be suspended until some child process terminates.
If the child exits with, say, 4 as the parameter to
exit(status),
the parent will be awakened with n set to the child’s
PID,
and statloc set to 0x0400.
04 is in the high order byte (the first half).
The C convention of prefixes hexadecimal constants with
0x.
Processes in MINIX3 have their memory divided up into three
segments:
1. the text segment (i.e., the program code),
2. the data segment (i.e., the variables), and
3. the stack segment.
The data segment grows upward, and the stack grows downward, as shown
below.
Between them is a gap of unused address space.
The stack grows into the gap automatically as needed,
but expansion of the data segment is done explicitly,
The data segment is expanded using a system call,
brk,
which specifies the new address where the data segment is to end.
size = brk(addr)
This address may be more than the current value (data segment is
growing),
or less than the current value (data segment is shrinking).
The parameter address must be lesser in value than the stack pointer
address,
or the data and stack segments would overlap, which is forbidden.
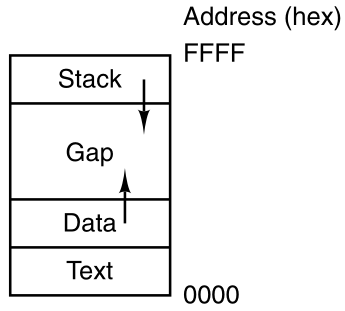
Processes have three segments:
text, data, and stack.
In this example, all three are in one address space,
but separate instruction and data space is also supported.
As a convenience for programmers,
a library routine sbrk is provided,
that also changes the size of the data segment,
Its parameter is the number of bytes to add to the data segment
(negative parameters make the data segment smaller).
It works by keeping track of the current size of the data segment,
which is the value returned by brk,
computing the new size,
and making a call asking for that number of bytes.
The brk and sbrk calls are not defined by the
POSIX standard,
and are extra in MINIX3
Why is this not in POSIX?
Programmers are encouraged to use the malloc library
procedure for dynamically allocating storage.
The underlying implementation of malloc was not thought to
be a suitable subject for standardization,
since few programmers use the underlying implementation directly.
The next process system call is also the simplest,
getpid.
It just returns the caller’s PID.
pid = getpid()
Remember that in fork, only the parent was given the
child’s PID.
If the child wants to find out its own PID,
then it must use getpid.
The getpgrp call returns the PID of the caller’s process
group:
pid = getgrp()
setsid creates a new session,
sets the process group’s PID to the caller’s,
and returns it’s process group id.
pid = setsid()
Sessions are related to an optional feature of POSIX, job control,
which is not supported by MINIX3,
and which will not concern us further.
The last process management system call, ptrace,
is used by debugging programs,
to control the program being debugged.
It allows the debugger to read and write the controlled processes’
memory,
and manage it in other ways.
l = ptrace(req, pid, addr, data)
++++++++++++++++ Cahoot-01-1
Although most forms of inter-process communication are planned,
situations exist in which unexpected communication is needed.
For example,
if a user accidentally tells a text editor to list the entire contents
of a very long file,
and then realizes the error,
some way is needed to interrupt the editor.
In MINIX3, the user can hit the CTRL-C key on the keyboard,
which sends a signal to the editor.
The editor catches the signal, and stops the print-out.
Signals can also be used to report certain traps detected by the
hardware,
such as illegal instruction, or floating point overflow.
Timeouts are also implemented as signals.
When a signal is sent to a unprepared process,
that has not announced its willingness to accept that signal,
the process is simply killed without further ado.
To avoid this fate,
a process can use the sigaction system call,
to announce that it is prepared to accept some signal type,
to provide the address of the signal handling procedure,
and a place to store the address of the current procedure.
s = sigaction(sig, &act, &oldact)
The sigaction call replaces the older
signal call,
which is now provided as a library procedure for backward
compatibility.
If a signal of the relevant type is generated
(e.g., by pressing CTRL-C),
then the state of the process is pushed onto its own stack,
and then the signal handler is called.
It may run for as long as it wants to,
and perform any system calls it wants to.
In practice, though, signal handlers are usually fairly short.
When the signal handling procedure is done, it calls
sigreturn,
to continue where it left off before the signal.
s = sigreturn(&context)
Signals can be blocked in MINIX3.
A blocked signal is held pending until it is unblocked.
It is not delivered, but also not lost.
The sigprocmask call allows a process to define the set of
blocked signals,
by presenting the kernel with a bitmap.
s = sigprocmask(how, &set, &old)
A process asks the set of signals currently pending,
but not allowed to be delivered, due to their being blocked.
The sigpending call returns this set as a bitmap.
s = sigpending(set)
A process can atomically set the bitmap of blocked signals and
suspend itself:
s = sigsuspend(sigmask)
Instead of providing a function to catch a signal,
the program may also specify the constant SIG_IGN,
to have all subsequent signals of the specified type ignored,
or SIG_DFL to restore the default action of the signal when
it occurs.
The default action is either to kill the process,
or ignore the signal, depending upon the signal.
As an example of how SIG_IGN is used,
consider what happens when the shell forks off a background process as a
result of
command &
It would be undesirable for a SIGINT signal (generated by
pressing CTRL-C)
to affect the background process,
so after the fork but before the exec, the shell does:
sigaction(SIGINT, SIG_IGN, NULL);
and
sigaction(SIGQUIT, SIG_IGN, NULL);
to disable the SIGINT and SIGQUIT
signals.
SIGQUIT is generated by CTRL-\;
it is the same as SIGINT generated by
CTRL-C,
except that, if it is not caught or ignored,
then it makes a core dump of the process killed.
For foreground processes (no ampersand),
these signals are not ignored.
Hitting CTRL-C is not the only way to send a
signal.
The kill system call allows a process to signal another
process
(provided they have the same UID,
unrelated processes cannot signal each other).
s = kill(pid, sig)
Getting back to the example of background processes used above,
suppose a background process is started up,
but later it is decided that the process should be terminated.
SIGINT and SIGQUIT have been disabled,
so something else is needed.
The solution is to use the kill program,
which uses the kill system call to send a signal to any process.
By sending signal 9 (SIGKILL) to a background
process,
that process can be killed.
SIGKILL cannot be caught or ignored.
Demonstrate this at the command line!
For many real-time applications,
a process needs to be interrupted after a specific time interval to do
something,
such as to re-transmit a potentially lost packet over an unreliable
communication line.
To handle this situation, the alarm system call has been
provided:
residual = alarm(seconds)
The parameter specifies an interval, in seconds,
after which a SIGALRM signal is sent to the process.
A process may only have one alarm outstanding at any instant.
If an alarm call is made with a parameter of 10 seconds,
and then 3 seconds later another alarm call is made with a parameter of
20 seconds,
only one signal will be generated, 20 seconds after the second
call.
The first signal is canceled by the second call to alarm.
If the parameter to alarm is zero,
then any pending alarm signal is canceled.
If an alarm signal is not caught,
then the default action is taken,
and the signaled process is killed.
It sometimes occurs that a process has nothing to do until a signal arrives.
For example, consider a educational program,
that is testing reading speed and comprehension.
It displays some text on the screen,
and then calls alarm to signal the program after 30
seconds.
While the student is reading the text,
the program has nothing to do.
It could spin a “tight loop” doing nothing,
but that would waste CPU time that another process or user might
need.
A better idea is to use pause,
which tells MINIX3 to suspend the process until the next signal:
s = pause()
++++++++++++++++ Cahoot-01-2
Many system calls involve the file system.
In this section we will look at calls that operate on individual
files;
in the next one we will examine those that involve directories or the
file system as a whole.
To create a new file, the creat call is used.
fd = creat(name, mode)
(why the call is creat and not create has been
lost in the mists of time).
Its parameters provide the name of the file and the protection
mode.
For example:
fd = creat("abc", 0751);
creates a file called abc with mode 0751
octal
(in the C programming language, a leading zero means that a constant is
in octal).
The low-order 9 bits of 0751 specify the rwx
bits for the owner
(7 means read-write-execute permission),
the group (5 means read-execute),
and others (1 means execute only).
creat not only creates a new file,
but also opens it for writing,
regardless of the file’s mode.
The file descriptor returned, fd,
can be used to write the file.
If a creat is done on an existing file,
that file is truncated to length 0,
provided, of course, that the permissions are all right.
The creat call is obsolete, as open can now
create new files.
Special files are created using mknod rather than
creat.
A typical call is:
fd = mknod("/dev/ttyc2", 020744, 0x0402)
which creates a file named /dev/ttyc2 (the usual name for
console 2),
and gives it mode 020744 octal
(a character special file with protection bits
rwx r-- r--).
The third parameter contains the major device (4) in the high-order
byte,
and the minor device (2) in the low-order byte.
The major device could have been anything,
but a file named /dev/ttyc2 ought to be minor device
2.
Calls to mknod fail unless the caller is the superuser.
To read or write an existing file,
the file must first be opened using open.
fd = open(file, how, ...)
This call specifies the file name to be opened,
either as an absolute path name or relative to the working
directory,
and a code of O_RDONLY, O_WRONLY, or
O_RDWR,
meaning open for reading, writing, or both.
The file descriptor returned can then be used for reading or
writing.
Afterward, the file can be closed by close,
which makes the file descriptor available for reuse on a subsequent
creat or open.
s = close(fd)
The most heavily used calls are undoubtedly read and
write.
We saw read earlier;
n = read(fd, buffer, nbytes)
write has the same parameters:
n = write(fd, buffer, nbytes)
the first one specifying the file descriptor,
the second one specifying the buffer, and
the third one specifying the number of bytes to
read.
Although most programs read and write files
sequentially,
for some applications programs need to be able to access any part of a
file at random.
Associated with each file is a pointer that indicates the current
position in the file.
When reading (writing) sequentially,
it normally points to the next byte to be read (written).
The lseek call changes the value of the position
pointer,
so that subsequent calls to read or write can begin anywhere in the
file,
or even beyond the end.
pos = lseek(fd, offset, whence)
lseek has three parameters:
the first is the file descriptor for the file,
the second is a file position, and
the third tells whether the file position is:
relative to the beginning of the file,
the current position, or
the end of the file.
The value returned by lseek is the absolute position in
the file,
after changing the pointer.
For each file, MINIX3 keeps track of the file mode
(regular file, special file, directory, and so on),
size, time of last modification, and other information.
Programs can ask to see this information via the stat and
fstat system calls.
These differ only in that the former specifies the file by
name,
s = stat(name, &buf)
whereas the latter takes a file descriptor,
s = fstat(fd, &buf)
making it useful for open files,
especially standard input and standard output,
whose names may not be known.
Both calls provide as the second parameter,
a pointer to a structure where the information is to be put.
The structure is shown below:
struct stat {
/* device where i-node belongs */
short st_dev;
/* i-node number */
unsigned short st_ino;
/* mode word */
unsigned short st_mode;
/* number of links */
short st_nlink;
/* user id */
short st_uid;
/* group id */
short st_gid;
/* major/minor device for special files */
short st_rdev;
/* file size */
long st_size;
/* time of last access */
long st_atime;
/* time of last modification */
long st_mtime;
/* time of last change to i-node */
long st_ctime;
};Demonstrate stat at shell terminal.
When manipulating file descriptors,
the dup call is occasionally helpful.
fd = dup(fd)
Implicit behavior:
Assigns the lowest existing file descriptor!
For example, a program that needs to close standard output (file
descriptor 1),
substitute another file as standard output,
call a function that writes some output onto standard output,
and then restore the original situation.
Just closing file descriptor 1 and then opening a new file,
will make the new file standard output
(assuming standard input, file descriptor 0, is in use),
but it will be impossible to restore the original situation later.
The solution is first to execute the statement:
fd = dup(1);
which uses the dup system call to allocate a new file
descriptor, fd,
and arrange for it to correspond to the same file as standard
output.
Then standard output can be closed,
and a new file opened and used.
When it is time to restore the original situation,
file descriptor 1 can be closed, and then:
n = dup(fd);
executed to assign the lowest file descriptor,
namely, 1, to the same file as fd.
Finally, fd can be closed and we are back where we
started.
The dup call has a variant,
where an arbitrary unassigned file descriptor refers to a given open
file.
It is called by:
dup2(fd, fd2);
where fd refers to an open file,
and fd2 is the unassigned file descriptor that is to be
made to refer to the same file as fd.
Thus, if fd refers to standard input (file descriptor
0) and fd2 is 4,
after the call, file descriptors 0 and 4 will
both refer to standard input.
Recall:
https://en.wikipedia.org/wiki/File_descriptor
Integer value Name <unistd.h> symbolic constant <stdio.h> file stream
0 Standard input STDIN_FILENO stdin
1 Standard output STDOUT_FILENO stdout
2 Standard error STDERR_FILENO stderrInterestingly, standard input and output are file descriptors,
like those you get when you execute open!
Inter-process communication in MINIX3 uses pipes.
When a user types:
cat file1 file2 | sort
the shell creates a pipe,
and arranges for standard output of the first process to write to the
pipe,
so standard input of the second process can read from it.
The pipe system call creates a pipe and returns two file
descriptors,
one for writing and one for reading:
s = pipe(&fd[0]);
where fd is an array of two integers,
fd[0] is the file descriptor for reading, and
fd[1] is the one for writing.
Typically, a fork comes next,
the parent closes the file descriptor for reading,
and the child closes the file descriptor for writing (or vice
versa),
so when they are done,
one process can read the pipe,
and the other can write on it.
The code below depicts a skeleton procedure that creates two
processes,
with the output of the first one piped into the second one.
A more realistic example would do error checking and handle
arguments…
/* file descriptor for standard input */
#define STD_INPUT 0
/* file descriptor for standard output */
#define STD_OUTPUT 1
pipeline(process1, process2)
/* pointers to program names */
char *process1, *process2;
{
int fd[2];
pipe(&fd[0]); /* create a pipe */
if (fork() != 0) {
/* The parent process executes these statements.*/
close(fd[0]); /* process 1 does not need to read from pipe */
close(STD_OUTPUT); /* prepare for new standard output */
dup(fd[1]); /* set standard output to fd[1] */
close(fd[1]); /* this file descriptor not needed any more */
execl(process1, process1, 0);
} else {
/* The child process executes these statements.*/
close(fd[1]); /* process 2 does not need to write to pipe */
close(STD_INPUT); /* prepare for new standard input */
dup(fd[0]); /* set standard input to fd[0] */
close(fd[0]); /* this file descriptor not needed any more */
execl(process2, process2, 0);
}
}A skeleton for setting up a two-process pipeline.
First a pipe is created, and then the procedure forks,
with the parent eventually becoming the first process in the
pipeline,
and the child process becoming the second one.
Since the files to be executed, process1 and
process2,
do not know that they are part of a pipeline,
it is essential that the file descriptors be manipulated,
so that the first process’ standard output be the pipe,
and the second one’s standard input be the pipe.
The parent first closes off the file descriptor for reading from the
pipe.
Then it closes standard output,
and does a dup call that allows file descriptor
1 to write on the pipe.
dup always returns the lowest available file descriptor, in
this case, 1.
Then the program closes the other pipe file descriptor.
After the exec call,
the process started will have file descriptors 0 and
2 be unchanged,
and file descriptor 1 for writing on the pipe.
The child code is analogous.
The parameter to execl is repeated,
because the first one is the file to be executed,
and the second one is the first parameter,
which most programs expect to be the file name.
ioctl is potentially applicable to all special
files.
It is used by block device drivers, like the SCSI driver,
to control tape storage, CD-ROM devices, or external disks.
Its main use however, is with special character files,
primarily virtual terminals.
POSIX defines a number of functions,
which the library translates into ioctl calls.
The tcgetattr and tcsetattr library
functions use ioctl,
to change the characters used for correcting typing errors on the
terminal,
changing the terminal mode, and so forth.
Traditionally, there are three terminal modes:
cooked, raw, and cbreak.
Cooked mode
is the normal terminal mode,
in which the erase and kill characters work normally,
CTRL-S and CTRL-Q can be used for stopping and
starting terminal output,
CTRL-D means end of file,
CTRL-C generates an interrupt signal, and
CTRL-\ generates a quit signal to force a core dump.
Raw mode
all of the above functions are disabled;
consequently, every character is passed directly to the program,
with no special processing.
Furthermore, in raw mode,
a read from the terminal will give the program any characters that have
been typed,
even a partial line,
rather than waiting for a complete line to be typed,
as in cooked mode.
Screen editors often use this mode.
Cbreak mode
is in between.
The erase and kill characters for editing are disabled,
and CTRL-D, but CTRL-S, CTRL-Q,
CTRL-C, and CTRL-\ are enabled.
Like raw mode, partial lines can be returned to programs
(if intra-line editing is turned off,
there is no need to wait until a whole line has been received;
the user cannot change their mind and delete it,
as one can in cooked mode).
POSIX does not use the terms cooked, raw,
and cbreak.
In POSIX terminology canonical mode corresponds to cooked
mode.
In this mode there are eleven special characters defined,
and input is by lines.
In non-canonical mode a minimum number of characters to accept and a
time,
specified in units of 1/10th of a second,
determine how a read will be satisfied.
Under POSIX there is a great deal of flexibility,
and various flags can be set to make noncanonical mode behave like
either cbreak or raw mode.
The older terms are more descriptive,
and we will continue to use them informally.
ioctl has three parameters:
s = ioctl(fd, request, argp)
For example a call to tcsetattr to set terminal
parameters will result in:
ioctl(fd, TCSETS, &termios);
The first parameter specifies a file descriptor,
the second parameter specifies an operation,
and the third parameter is the address of a POSIX data
structure,
that contains flags and the array of control characters.
Other operation codes instruct the system to:
postpone the changes until all output has been sent,
cause unread input to be discarded,
and return the current values.
The access system call determines whether a file access
is permitted by the protection system:
s = access(name, amode)
It is needed because some programs can run using a different user’s
UID.
This SETUID mechanism and access will be described later
also.
The rename system call is used to give a file a new
name:
s = rename(old, new)
The parameters specify the old and new names.
Finally, the fcntl call is used to control files,
somewhat analogous to ioctl
(i.e., both of them are horrible hacks).
s = fcntl(fd, cmd, ...)
It has several options,
the most important of which is for advisory file locking.
Using fcntl, it is possible for a process to lock and
unlock parts of files,
and test part of a file to see if it is locked.
The call does not enforce any lock semantics.
Programs must do this themselves.
++++++++++++++++ Cahoot-01-3
Now, we review system calls that involve directories,
or the file system as a whole,
rather than just to one specific file,
as in the previous section.
The first two calls, mkdir and rmdir,
create and remove empty directories, respectively.
s = mkdir(name, mode)
s = rmdir(name)
The next call is link.
Its purpose is to allow the same file to appear under two or more
names,
often in different directories.
s = link(name1, name2)
A typical use allows several members of the same programming team to
share a common file,
with each of them having the file appear in his own directory,
possibly under different names.
Sharing a file is not the same as giving every team member a private
copy,
Changes that any member of the team makes are instantly visible to the
other members;
there is only one file.
When copies are made of a file,
subsequent changes made to one copy do not affect the other ones.
To see how link works, consider the situation of the image
below.

Here are two users, ast and jim,
each having their own directories with some files.
If ast now executes a program containing the system
call
link("/usr/jim/memo", "/usr/ast/note");
the file memo in jim’s directory is now entered into ast’s
directory under the name note.
Thereafter, /usr/jim/memo and /usr/ast/note
refer to the same file.
Understanding how link works will probably make it clearer what it
does.
Every file in UNIX has a unique number,
its i-number, that identifies it.
Demonstrate i-node inspection:
stat <file>
ls -i <file>
And linking:
man ln
echo stuff >file1.txt
ln file1.txt file2.txt
echo morestuff >>file2.txt
cat file1.txt
stat file1.txt
stat file2.txt
rm file1.txt
ls
This i-number is an index into a table of i-nodes, one per
file,
telling who owns the file, where its disk blocks are, and so on.
A directory is simply a file containing a set of (i-number, ASCII name)
pairs.
In the first versions of UNIX,
each directory entry was 16 bytes,
2 bytes for the i-number,
and 14 bytes for the name.
A more complicated structure is needed to support long file names,
but conceptually a directory is still a set of (i-number, ASCII name)
pairs.
In the image above, mail has i-number 16,
and so on.
What link does is simply create a new directory entry (a
file),
with a (possibly new) name,
using the i-number of an existing file.
In the image, two entries have the same i-number
(70),
and thus refer to the same file.
If either one is later removed,
using the unlink system call,
the other one remains.
s = unlink(name)
Only if all links are removed,
and UNIX sees that no entries to the file exist,
is the file removed from the disk.
A field in the i-node data keeps track of the number of directory
entries pointing to the file.
As we have mentioned earlier,
the mount system call allows two file systems to be merged
into one.
A common situation is to have the root file system,
containing the binary (executable) versions of the common
commands,
and other heavily used files, both on a hard disk.
The user can then insert an external drive or disk.
By executing the mount system call,
the disk file system can be attached to the root file system,
as shown below:
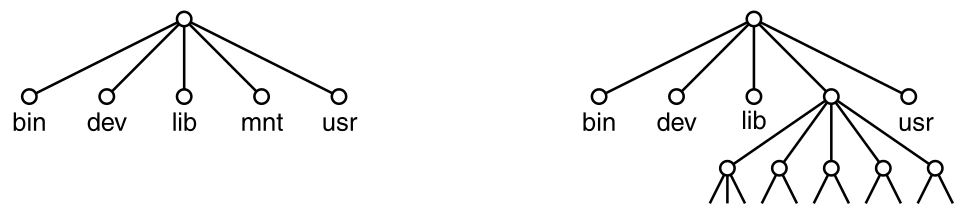
(a) File system before the mount.
(b) File system after the mount.
Generally,
s = mount(special, name, flag)
A typical statement in C to perform the mount is:
mount("/dev/cdrom0", "/mnt", 0)
where the first parameter is the name of a block special file for
external disk drive 0,
the second parameter is the place in the tree where it is to be mounted,
and
the third one tells whether the file system is to be mounted read-write
or read-only.
After the mount call,
a file on disk drive 0 can be accessed,
by just using its path from the root directory or the working
directory,
without regard to which drive it is on.
In fact, second, third, and fourth drives can also be mounted
anywhere in the tree.
The mount call makes it possible to integrate removable media,
into a single integrated file hierarchy,
without having to worry about which device a file is on.
Although this example involves whole disks,
hard disks or portions of hard disks
(often called partitions or minor devices)
can also be mounted this way.
When a file system is no longer needed,
it can be unmounted with the umount system call.
s = umount(special)
MINIX3 maintains a block cache, of recently used blocks, in main
memory,
to avoid having to read them from the disk, if they are used again
quickly.
If a block in the cache is modified by a write on a file,
and the system crashes before the modified block is written out to
disk,
the file system will be damaged.
To limit the potential damage,
it is important to flush the cache periodically,
so that the amount of data lost by a crash will be small.
sync writes out all the cache blocks that have been
modified, since being read in.
s = sync()
When MINIX3 is started up,
a program called update is started as a background
process,
to do a sync every 30 seconds, to keep flushing the
cache.
Two other calls that relate to directories are chdir and
chroot.
The former changes the working directory:
s = chdir(dirname)
and the latter changes the root directory:
s = chroot(dirname)
For example, after the call
chdir("/usr/ast/test");
an open on the file xyz will open
/usr/ast/test/xyz.
chroot works in an analogous way.
Once a process has told the system to change its root directory,
all absolute path names (path names beginning with a “/”),
will start at the new root.
Why would you want to do that?
For security, server programs for protocols such as:
FTP (File Transfer Protocol) and
HTTP (HyperText Transfer Protocol)
all do this,
so remote users of these services can access only the portions of a file
system below the new root.
Only superusers may execute chroot,
and even superusers do not do it very often.
This is the precursor to the chroot jail, and modern Docker or OCI containers!
++++++++++++++++ Cahoot-01-4
In MINIX3 every file has an 11-bit mode used for protection of the
filesystem.
Nine of these bits are the read-write-execute bits for the owner, group,
and others.
If you are still curious about the functional high level POSIX interface
for these:
../../Security/Content/19b-Permissions.html
The chmod system call makes it possible to change the
mode of a file.
s = chmod(name, mode)
For example, to make a file read-only by everyone except the
owner,
one could execute:
chmod("file", 0644);
The other two protection bits, 02000 and
04000,
are the SETGID (set-groupid) and SETUID (set-user-id) bits,
respectively.
When any user executes a program with the SETUID bit on,
for the duration of that process,
the user’s effective UID is changed to that of the file’s owner.
This feature is used to allow users to execute programs that perform
superuser only functions,
such as creating directories.
Creating a directory uses mknod,
which is for the superuser only.
By arranging for the mkdir program to be owned by the
superuser,
and have mode 04755,
ordinary users can be given the power to execute
mknod,
but in a highly restricted way.
When a process executes a file that has the SETUID or SETGID bit on
in its mode,
it acquires an effective UID or GID different from its real UID or
GID.
It is sometimes important for a process to find out what its real and
effective UID or GID is.
The system calls getuid and getgid have been
provided to supply this information.
Each system call returns both the real and effective UID or GID:
uid = getuid()
gid = getgid()
Four library routines are needed to extract the proper
information:
getuid, getgid, geteuid, and
getegid.
The first two get the real UID/GID,
and the last two the effective ones.
Ordinary users cannot change their UID,
except by executing programs with the SETUID bit on,
but the superuser has another possibility:
The setuid system call,
which sets both the effective and real UIDs.
s = setuid(uid)
setgid sets both GIDs
s = setgid(gid)
The superuser can also change the owner of a file,
with the chown system call.
s = chown(name, owner, group)
The superuser has plenty of opportunity for violating all the
protection rules!
The last two system calls in this category can be executed by ordinary
user processes.
The first one, umask,
sets an internal bit mask within the system,
which is used to mask off mode bits when a file is created:
oldmask = umask(complmode)
For example, after the call
umask(022);
the default mode supplied by creat and mknod
are changed,
and will have the 022 bits masked off (subtracted) before
being used.
Thus the call:
creat("file", 0777);
will set the mode to 0755 rather than
0777.
Since the bit mask is inherited by child processes,
if the shell does a umask just after login,
none of the user’s processes in that session will accidently create
unprotected files,
that other people can write on.
When a program owned by the root has the SETUID bit
on,
it can access any file,
because its effective UID is the superuser.
A program may query if the process (person) who called the program
has permission to access a given file.
If the program just tries the access,
it will always succeed, and thus learn nothing.
What is needed is a way to see if the access is permitted for the real
UID.
The access system call provides a way to find out.
s = access(name, amode)
The mode parameter is:
4 to check for read access,
2 for write access, and
1 for execute access.
Combinations of these values are also allowed.
For example, with mode equal to 6,
the call returns 0 if both read and write access are
allowed for the real ID;
otherwise -1 is returned.
With mode equal to 0, a
check is made to see if the file exists,
and the directories leading up to it can be searched.
Although the protection mechanisms of all UNIX-like operating systems
are generally similar,
there are some differences and inconsistencies.
++++++++++++++++ Cahoot-01-5
MINIX3 has four system calls that involve the time-of-day clock.
time just returns the current time in seconds,
with 0 corresponding to Jan. 1, 1970 at midnight
(just as the day was starting, not ending).
seconds = time(&seconds)
The system clock must be set at some point in order to allow it to be
read later,
so stime has been provided,
to let the clock be set (by the superuser).
s = stime(tp)
The third time call is utime,
which allows the owner of a file (or the superuser)
to change the time stored in a file’s i-node:
s = utime(file, timep)
Application of this system call is fairly limited,
but a few programs need it,
for example the shell program, touch,
which sets the file’s time to the current time.
Finally, we have times,
which returns the accounting information to a process,
so it can see how much CPU time it has used directly,
and how much CPU time the system itself has expended on its behalf
(handling its system calls).
The total user and system times used by all of its children combined are
also returned.
s = times(buffer)