Previous: 01-Overview.html
document.querySelector('video').playbackRate = 1.2“Web users ultimately want to get at data quickly and
easily.
They don’t care as much about attractive sites and pretty
design.”
- Tim Berners-Lee
Is this assumption currently true?
Was it ever true?
Is it true for some people at least?
Overview, HTTP, email, FTP, DNS, P2P, Multimedia (CDN, P2P), Socket programming intro.
Reading:
https://www.computer-networking.info/1st/html/index.html
(Part 2: The application layer)
https://www.binarytides.com/netcat-tutorial-for-beginners/
(instead of telnet!)
Kurose chapter 2
Principles of network applications
Web and HTTP
Electronic mail: SMTP, POP3, IMAP
DNS
P2P applications
Socket programming with UDP and TCP
Classic text-based applications that became popular in the 1970s and
1980s:
text email, remote access to computers, file transfers, and
newsgroups.
Killer application of the mid-1990s:
the World Wide Web, encompassing Web surfing, search, and electronic
commerce.
Instant messaging and P2P file sharing, the two killer applications
introduced at the end of the millennium.
Since 2000, voice-over-IP (VoIP), YouTube, Netflix, World of Warcraft,
Facebook, and Twitter
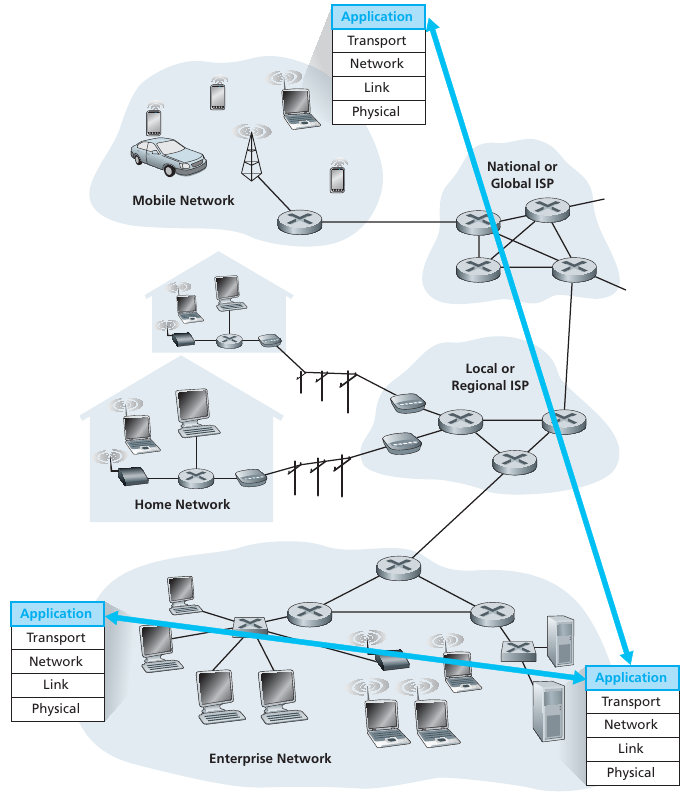
End system communication at application layer
Goal: write programs that:
run on (different) end systems,
communicate over network, e.g.,
web server software communicates with browser software
No need (or desire) to write software for network-core devices:
Network-core devices do not (and SHOULD not) run user
applications!
Applications on end systems allows for rapid app development,
propagation, and innovation.
This is changing somewhat, which could impede the development of new
protocols.
Client-server versus peer-to-peer (P2P)
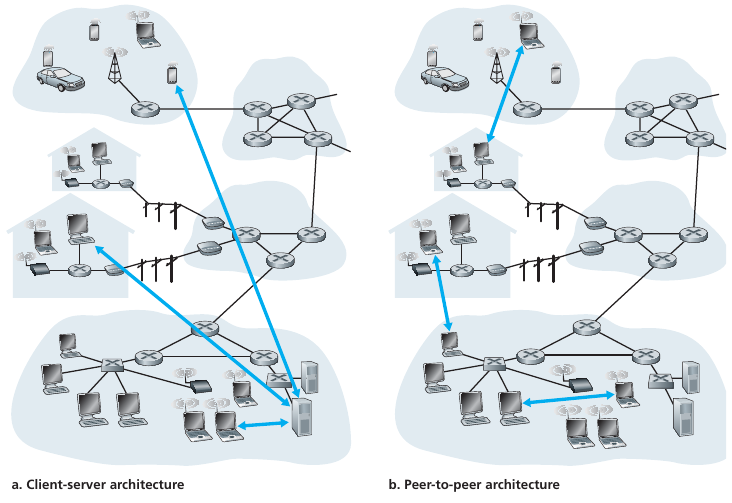

Always-on host, called the server, which services requests from many
other hosts, called clients.
Permanent addresses are either an IP address, or
overlay/hash address of some kind, in the case of IP-anonymizing
networks
Web server services requests from browsers running on client
hosts.
When a Web server receives a request for an object from a client
host,
it responds by sending the requested object to the client host.
Now in data centers for scaling
Communicate with server.
May be intermittently connected.
May have dynamic IP addresses (or dynamically changing overlay
addresses).
Do not usually communicate directly with each other (unless hybrid
client-server/p2p with p2p).
Minimal (or no) reliance on dedicated servers in data centers.
Direct communication between pairs of intermittently connected hosts,
called peers.
The peers are not owned by the service provider,
but are instead desktops and laptops controlled by users,
with most of the peers residing in homes, universities, and
offices.
Peers request service from other peers, provide service in return to
other peers
Self-scalabile, since each peer adds service capacity to the system by
distributing files to other peers.
Cost effective, since they normally don’t require significant server
infrastructure and server bandwidth
(in contrast with clients-server designs with data centers).
Peers often exchange IP addresses (or overlay addresses,
e.g., onion, garlic routing and crypto addresses).
Complex management, implementation, debugging?
++++++++++++++ Cahoot-02-1
Discussion question:
If p2p works well, why has it not become the norm?
What are some other pros/cons of p2p architectures?
This is a hint of the next layer, transport
It’s not actually programs, but processes that
communicate with each other.
A process is assigned by OS to a program that is running within an end
system.
When processes are running on the same end system,
they can communicate with each other with inter-process communication
(IPC).
Processes on two different end systems communicate with each
other,
by exchanging messages across the computer
network.
A sending process creates and sends messages into the network.
A receiving process receives these messages and possibly responds by
sending messages back.
A process initiates the communication by initially contacting the other
process at the beginning of the session.
The initiator labeled as the client.
The process that waits to be contacted to begin the session is nominally
the server.
Client process: process that initiates communication.
Server process: process that waits to be contacted.
Aside: applications with P2P architectures have both client processes and server processes.
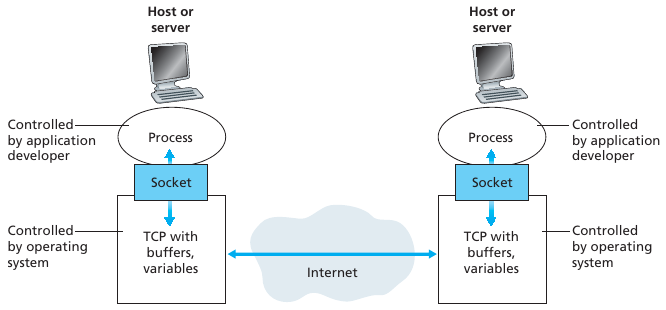
Any message sent from one process to another must go through the
underlying network.
A process sends messages into, and receives messages from, the
network,
through an OS-defined software interface called a
socket.
A socket is the interface between the application layer and the
transport layer within a host OS.
It is also referred to as the Application Programming Interface (API)
between the application and the network,
since the socket is the programming interface with which network
applications are built.
To receive messages, process must have identifier
Q: does the IP address of a host, on which a process runs, suffice
for identifying the process?
A: no, many processes can be running on one host
In order for a process running on one host to send packets to a
process running on another host,
the receiving process needs to have an address with
both:
an address of the host OS itself (IP), and
an identifier that specifies the specific receiving process in the
destination host OS (port).
Popular applications have been assigned specific port numbers,
e.g.,
A Web server (using the HTTP protocol) is usually identified by port
number 80.
A mail server process (using the SMTP protocol) is usually identified by
port number 25.
An SSH server is usually identified on port number 22
For example, to send HTTP message to gaia.cs.umass.edu web server:
IP address: 128.119.245.12
port number: 80
Hosts are often identified by IP address:
IP address is a 32-bit quantity uniquely identifying
the host, in ipv4.
Addresses are 128 bit for ipv6.
We ran out of ipv4 addresses…
The sending process must also identify the receiving process (more
specifically, the receiving socket) running in the host.
This information is needed because in general a host could be running
many network applications.
A destination port number serves this purpose.
++++++++++++++ Cahoot-02-2
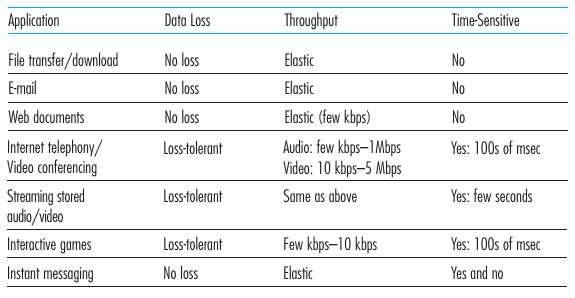
Data integrity
Some apps (e.g., file transfer, web transactions) require 100% reliable
data transfer.
Other apps (e.g., audio) can tolerate some loss.
Timing
Some apps (e.g., Internet telephony, interactive games) require low
delay to be “effective”.
Some apps (e.g., file download) tolerate delay.
Throughput
Some apps (e.g., multimedia) require minimum amount of throughput to be
“effective”.
Other apps (“elastic apps”) make use of whatever throughput they
get.
Security
Encryption, data integrity, …
Unreliable datagram (UDP)

Byte-stream (TCP)
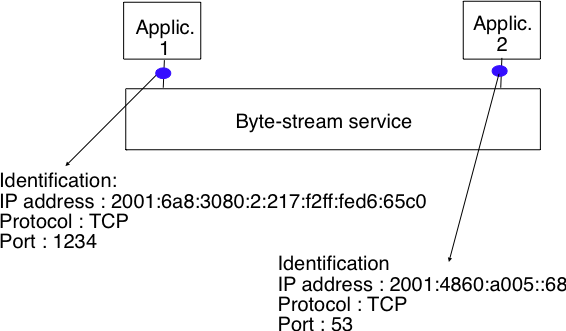
Service requirements for applications?
Applications usually choose between TCP and
UDP
TCP and UDP are transport layer.
Employed by most application layer programs.
Other Transport layer, or pseudo-transport layer protocols exist.
SCTP (stream control transmission protocol), SSU (I2P app), DCCP, RUDP,
UDP-lite, etc.
An application designer could design their own transport layer
protocol,
since Transport layer and up runs on end hosts, as opposed to network
infrastructure.
Could build into the core/kernel of end operating systems and languages
as new socket type.
Could also just design the features into the application layer,
rather than actually get a transport protocol built into the kernel of
an OS.
UDP lets you build new things!
Connection-oriented service
TCP has the client and server exchange transport-layer control
information with each other,
before the application-level messages begin to flow.
This so-called handshaking procedure alerts the client and server,
allowing them to prepare for an onslaught of packets.
After the handshaking phase,
a TCP connection is said to exist between the sockets of the two
processes.
The connection is a full-duplex connection,
in that the two processes can both send messages to each other,
over the connection at the same time, bi-directionally
When the application finishes sending messages,
it must tear down the connection.
TCP has a Reliable data transfer service
The communicating processes can rely on TCP to deliver all data sent
without error and in the proper order.
TCP also includes a congestion-control
mechanism
The TCP congestion-control mechanism throttles a sending process (client
or server),
when the network is congested between sender and receiver.
Summary
Reliable transport: between sending and receiving
process.
Flow control: sender won’t overwhelm receiver.
Congestion control: throttle sender when network
overloaded.
Does not provide: timing, minimum throughput guarantee,
security.
Connection-oriented: setup required between client and
server processes.
UDP is a no-frills, lightweight transport protocol, providing minimal
services.
UDP is connectionless, so there is no handshaking before the two
processes start to communicate.
UDP provides an unreliable data transfer service.
When a process sends a message into a UDP socket,
UDP provides no guarantee that the message will ever reach the receiving
process.
Messages that do arrive at the receiving process may arrive out of
order.
UDP does not include a congestion-control mechanism,
so the sending side of UDP can attempt to pump data into the layer below
(the network layer) at any rate it pleases.
UDP service:
Provides: Unreliable data transfer between sending and receiving
process
Does not provide: Reliability, flow control, congestion control, timing,
throughput guarantee, security, or connection setup,
Discussion questions:
Why bother with UDP?
With TCP, why is there a UDP?
++++++++++++++ Cahoot-02-3
https://en.wikipedia.org/wiki/Transport_Layer_Security
Neither base TCP nor UDP provide any encryption!
An Enhancement for TCP provides:
1. encryption,
2. data integrity, and
3. end-point authentication.
The great thing about a TLS joke,
is that you can tell if it’s not the original…
This security enhancement used to be called called Secure
Sockets Layer (SSL).
Transport layer security (TLS) is just a newer version
of SSL.
SSL was the name of now-defunct versions of what is now modern
TLS.
TLS is not a third Internet transport protocol,
on the same level as TCP and UDP, but an enhancement of TCP, at the
application layer.
Applications needs to include TLS code (existing libraries) in both the
client and server sides of the application.
TLS has its own socket API that is similar to the traditional TCP socket
API.
sending process passes cleartext data to the SSL socket;
TLS in the sending host then encrypts the data and passes the encrypted
data to the TCP socket.
encrypted data travels over the Internet to the TCP socket in the
receiving process.
receiving socket passes the encrypted data to SSL, which decrypts the
data.
TLS passes the cleartext data through its SSL socket to the receiving
process.
TLS socket API is like that of a TCP socket (just import and use).
Transport layer protocols used
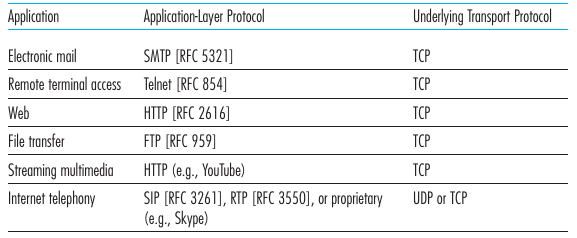
Tunneling:
Inner-most -> Outer-more… -> Outer-most
Application -> TLS -> TCP -> IP -> MAC -> Ethernet ->
Physical
More detail here:
05-Security.html
../../Security/Content/12a-AppliedCryptoSystems.html
An application-layer protocol defines how an
application’s processes,
running on different end systems, pass messages to each other, for
example:
The types of messages exchanged, for example,
request messages and response messages.
E.g., request, response.
The syntax of the various message types, such as the fields in the message and how the fields are delineated.
The semantics of the fields.
meaning of the information in the fields.
Rules for determining when and how a process sends messages and responds to messages, and change state.
Open protocols:
Defined in RFCs.
Allows for interoperability.
e.g., HTTP, SMTP
Proprietary protocols:
e.g., Skype (used to be open, fun story)
https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
https://tools.ietf.org/html/rfc7230 (HTTP, show
this)
https://media.pearsoncmg.com/aw/ecs_kurose_compnetwork_7/cw/content/interactiveanimations/http-delay-estimation/index.html
https://www.computer-networking.info/1st/html/application/http.html
https://www.computer-networking.info/2nd/html/protocols/http.html
Observe HTTP with Wireshark:
$ nc -C info.cern.ch 80
$ GET / HTTP/1.1
$ Host: info.cern.ch$ ncat -C hackware.ru 80
$ GET / HTTP/1.0
$ Host: hackware.ruTrace HTTP conversation in Wireshark
Observe each packet has headers from multiple layers
These must be typed exactly, or they will not
work!
ncat -C option is for crlf: $ man ncat to read
more
Encrypted option:
$ ncat -C --ssl hackware.ru 443
$ GET / HTTP/1.0
$ Host: hackware.ruHTTP: hypertext transfer protocol is the Web’s application layer protocol.
Client/Server model:
Client: Browser that requests, receives, (using HTTP
protocol) and “displays” Web objects.
Server: Web server sends (using HTTP protocol) objects
in response to requests.
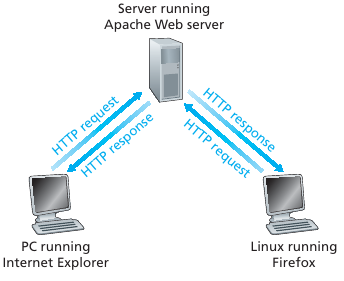
Web pages
A Web page (also called a document) consists of objects.
An object is simply a file such as an HTML file, a JPEG image, a Java
applet (lol…),
or a video clip that is addressable by a single URL.
If a Web page contains HTML text and five JPEG images,
then the Web page has six objects: the base HTML file plus the five
images.
The base HTML file references the other objects in the page with the
objects’ URLs.
Each URL has two components:
the hostname of the server that houses the object
and
the object’s path name.
For example, the URL:
http://www.someSchool.edu/someDepartment/picture.gif
has www.someSchool.edu for a hostname
and
/someDepartment/picture.gif for a path
name.

http://www.w3.org/MarkUp/ defines the standard
HTTP/1 and HTTP/2 use TCP (not UDP).
The HTTP client first initiates a TCP connection with the
server.
Once the connection is established, the browser and the server processes
access TCP through their socket interfaces.
Server sends requested files to clients without storing any state
information about the client, a stateless protocol.
Client initiates TCP connection (creates socket) to server, port 80
or 443.
server accepts TCP connection from client.
HTTP messages (application-layer protocol messages) exchanged between
browser (HTTP client) and Web server (HTTP server).
TCP connection closed.
HTTP is “stateless”.
Server maintains no information about past client requests as a part of
the protocol itself.
It could do so in other ways, but that would not be part of HTTP.
Protocols that maintain “state” are complex!
Past history (state) must be maintained.
If server/client crashes, their views of “state” may be inconsistent,
must be reconciled.
HTTP can choose either:
Each request/response pair sent over a separate TCP connection
(non-persistent connections), or
all of the requests and their corresponding responses sent over the same
TCP connection (persistent connections).
HTTP sequence
A base HTML file and 10 JPEG images, and that all 11 of these objects
reside on the same server:
<http://www.someSchool.edu/someDepartment/home.index>
HTTP client process initiates a TCP connection to the server https://www.someSchool.edu on port number 80,
which is the default port number for HTTP.
Associated with the TCP connection, there will be a socket at the client
and a socket at the server.
HTTP client sends an HTTP request message to the server via its
socket.
The request message includes the path name
/someDepartment/home.index.
HTTP server process receives the request message via its
socket,
retrieves the object /someDepartment/home.index from its
storage (RAM or disk),
encapsulates the object in an HTTP response message,
and sends the response message to the client via its socket.
HTTP server process tells TCP to close the TCP connection.
But TCP doesn’t actually terminate the connection,
until it knows for sure that the client has received the response
message intact.
HTTP client receives the response message.
The TCP connection terminates.
The message indicates that the encapsulated object is an HTML
file.
The client extracts the file from the response message, examines the
HTML file,
and finds references to the 10 JPEG objects.
first four steps are then repeated for each of the referenced JPEG objects.
Time to fill a request
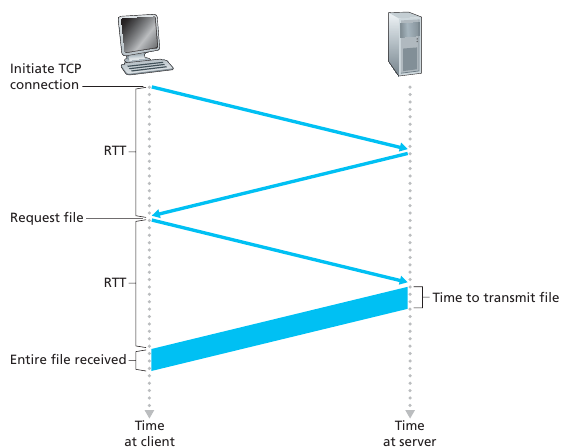
Non-persistent HTTP
At most one object sent over TCP connection.
Connection then closed.
Downloading multiple objects required multiple connections.
Persistent HTTP
Multiple objects can be sent over single TCP connection between client,
server
Disadvantages of non-persistent connections
First, a brand-new connection must be established and maintained for
each requested object.
For each of these connections, TCP buffers must be allocated and TCP
variables must be kept in both the client and server.
Each object suffers a delivery delay of two RTTs one RTT to establish
the TCP connection and one RTT to request and receive an object.
RTT (definition): time for a small packet to travel from client to server and back
HTTP response time:
One RTT to initiate TCP connection,
one RTT for HTTP request and first few bytes of HTTP response to
return,
plus the file transmission time.
Non-persistent HTTP response time:
2RTT + file transmission time.
Non-persistent HTTP issues:
Requires 2 RTTs per object
OS overhead for each TCP connection.
Browsers often open parallel TCP connections to fetch referenced
objects.
Persistent connections
With persistent connections, the server leaves the TCP connection open
after sending a response.
Subsequent requests and responses between the same client and server can
be sent over the same connection.
Multiple Web pages residing on the same server can be sent from the
server to the same client over a single persistent TCP connection.
Requests for objects can be made back-to-back, without waiting for
replies to pending requests (pipelining).
Typically, the HTTP server closes a connection when it isn’t used for a
certain time (a configurable timeout interval).
Persistent HTTP:
Server leaves connection open after sending response.
Subsequent HTTP messages between same client/server sent over open
connection.
Client sends requests as soon as it encounters a referenced
object.
As little as one RTT for all the referenced objects.
++++++++++++++ Cahoot-02-4
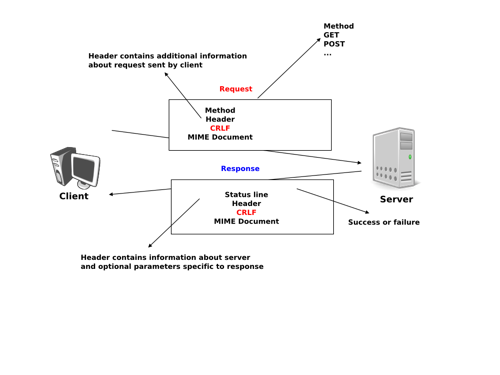
two types of HTTP messages:
1. request,
2. response
HTTP request message:
ASCII (human-readable format)
GET /somedir/page.html HTTP/1.1
Host: www.mst.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: enGeneral request
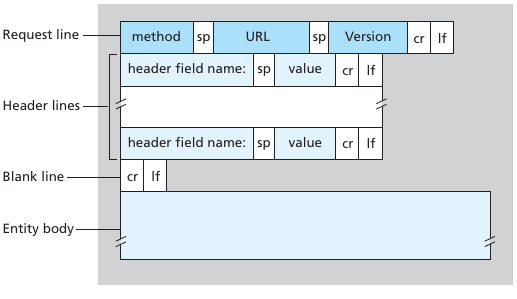
sp=space; cr=carriage return; lf=line feed
Example:
GET /index.html HTTP/1.1\r\n
Host: www-net.cs.umass.edu\r\n
User-Agent: Firefox/3.6.10\r\n
Accept: text/html,application/xhtml+xml\r\n
Accept-Language: en-us,en;q=0.5\r\n
Accept-Encoding: gzip,deflate\r\n
Accept-Charset: ISO-8859-1,utf-8;q=0.7\r\n
Keep-Alive: 115\r\n
Connection: keep-alive\r\n
\r\nHTTP/1.1 200 OK
Connection: close
Date: Tue, 09 Aug 2011 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ...
The entity body is the
meat of the message,
it contains the requested object itself)General reply
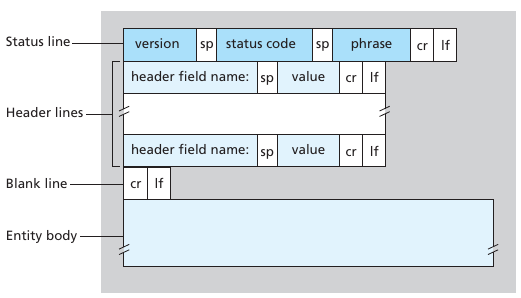
sp=space; cr=carriage return; lf=line feed
Example:
HTTP/1.1 200 OK\r\n
Date: Sun, 26 Sep 2010 20:09:20 GMT\r\n
Server: Apache/2.0.52 (CentOS)\r\n
Last-Modified: Tue, 30 Oct 2007 17:00:02 GMT\r\n
ETag: "17dc6-a5c-bf716880"\r\n
Accept-Ranges: bytes\r\n
Content-Length: 2652\r\n
Keep-Alive: timeout=10, max=100\r\n
Connection: Keep-Alive\r\n
Content-Type: text/html; charset=ISO-8859-1\r\n
\r\n
data data data data data ...Server responses
Status code appears in 1st line in server-to-client response
message.
The best thing about 404 jokes is …
wait, damnit, it’s around here somewhere…
418: I’m a teapot
A “real” joke built into the protocol
https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/418
https://en.wikipedia.org/wiki/Hyper_Text_Coffee_Pot_Control_Protocol
https://save418.com/
Old example: Open TCP connection, send GET request
telnet cis.poly.edu 80
GET /~ross/ HTTP/1.1
Host: cis.poly.eduE.g.,
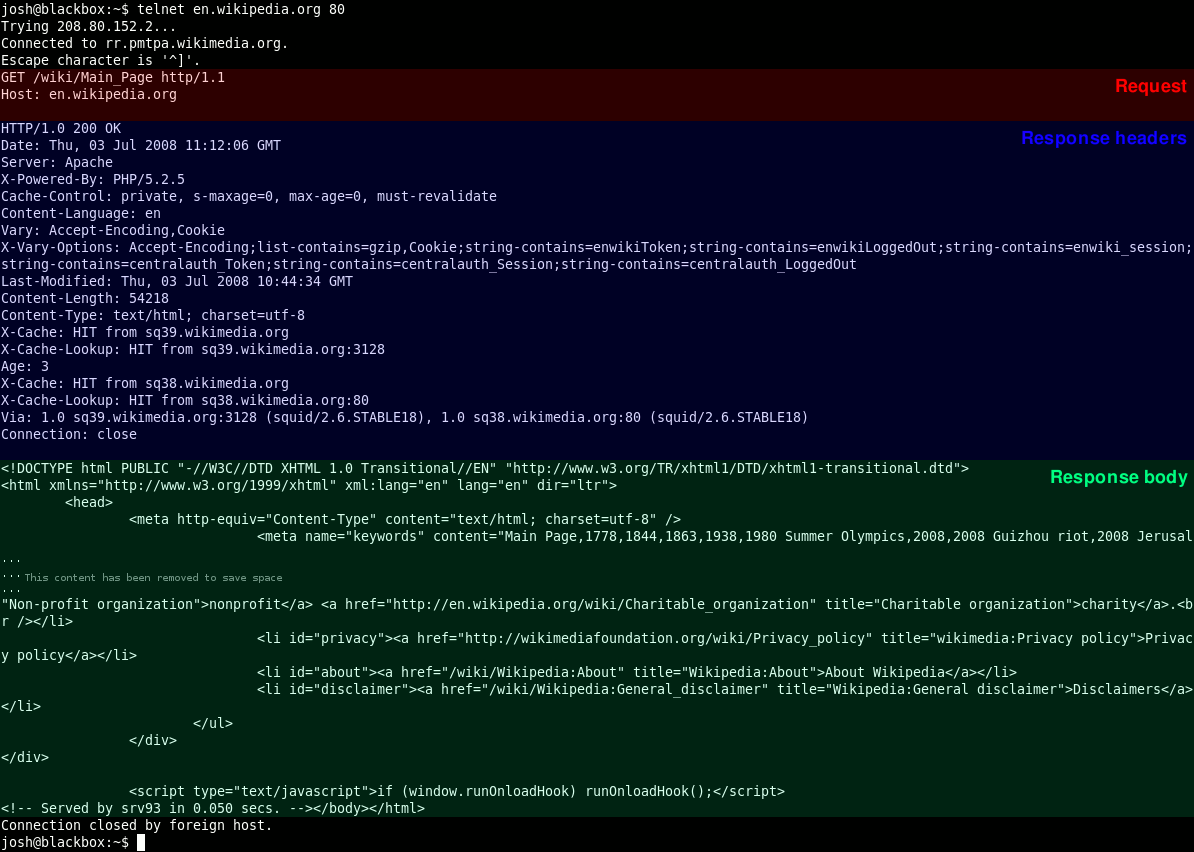
Note: ncat has generally replaced
telnet, though they both still work
nc -C info.cern.ch 80
GET / HTTP/1.1
Host: info.cern.chPOST method:
Web page often includes form input.
Input is uploaded to server in entity body (i.e., message part of
packet).
URL method:
Uses GET method.
Input is uploaded in URL field of request line:
www.somesite.com/animalsearch?monkeys&banana
We’ll demo this later!
HTTP/1.0:
GET
POST
HEAD (asks server to leave requested object out of response)
HTTP/1.1:
GET, POST, HEAD
PUT (uploads file in entity body to path specified in URL field)
DELETE (deletes file specified in the URL field)
Demonstrate:
More wireshark HTTP examples in detail
http://info.cern.ch/
via nc
via a browser that does not generate junk traffic:
epiphany or surf or
qutebrowser
Record it in Wireshark
Identify HTTP headers, match them to fields
Many Web sites use cookies.
Four components:
1) cookie header line of HTTP response message
2) cookie header line in next HTTP request message
3) cookie file kept on user’s host, managed by user’s browser
4) back-end database at Web site
Example:
Susan always access Internet from PC.
She visits specific e-commerce site for first time.
When initial HTTP requests arrives at site, site creates both a:
unique ID, and
entry in backend database for ID
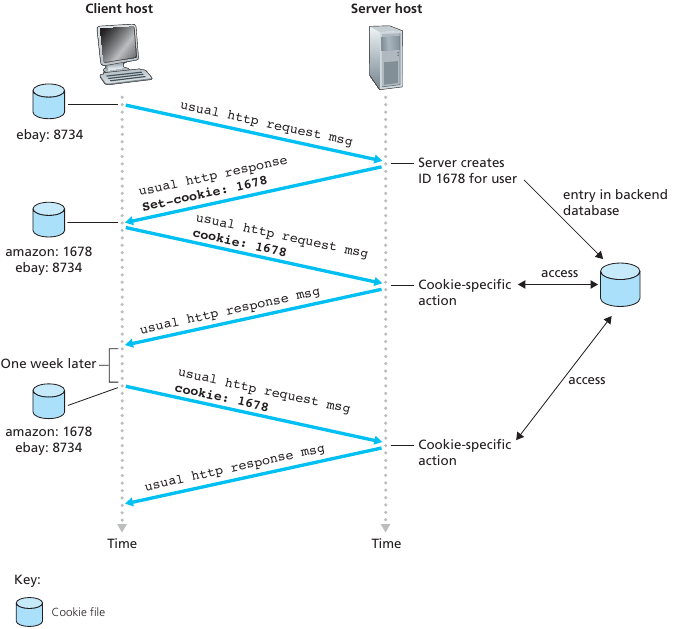
What cookies can be used for:
authorization,
shopping carts,
recommendations,
user session state (Web e-mail),
tracking.
How to keep “state”:
Protocol endpoints: maintain state at sender/receiver over multiple
transactions.
Cookies: http messages carry state.
Cookies and privacy:
Cookies permit sites to learn a lot about you.
You may supply name and e-mail to sites.
Proxy server can cache web file data.
Goal: satisfy client request without involving origin server.
User sets browser: Web accesses via cache.
Browser sends all HTTP requests to cache.
If object in cache, then cache returns object.
Else cache requests object from origin server
then returns object to client.
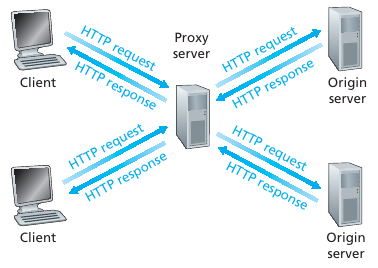
Bottleneck
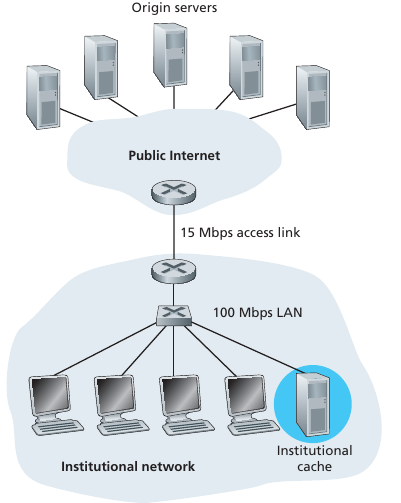
Caching helps bottleneck
Demos
Briefly show (not link) $ Webserver.py
Run it, show visiting in browser
<http://localhost:6789>
Sometimes UDP is used simply because it allows new or experimental
protocols to run entirely as user-space applications.
No kernel updates are required, as would be the case with TCP
changes.
Google has created a protocol named QUIC (Quick UDP Internet
Connections,
chromium.org/quic) in this category, rather specifically to support the
HTTP protocol.
QUIC can in fact be viewed as a transport protocol specifically tailored
to HTTPS:
HTTP plus TLS encryption.
Some interesting reading on QUIC (Google’s web protocol on top of
UDP):
http://intronetworks.cs.luc.edu/current2/uhtml/udp.html#quic
https://en.wikipedia.org/wiki/QUIC
https://daniel.haxx.se/blog/2018/11/11/http-3/
https://blog.cloudflare.com/the-road-to-quic/
Both innovative, and breaks federated interoperability, which has pros
and cons.
I received this HTTP 200 joke.
It was OK…
++++++++++++++ Cahoot-02-5
Simple file
http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file1.html
GET, OK, etc.
Refreshing a cached page
http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file2.html
IF-MODIFIED-SINCE, refresh, re-sent?
Large file
http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file3.html
Initial HTTP GET, TCP segments, how many HTTP OK, when?
Multiple-parts
http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file4.html
Notice the image retrieval.
What entity is responsible for requesting the multiple objects in a
page, when?
“Secure” web-page with login
http://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wireshark-file5.html
username: wireshark-students
password: network
auth field of request
#!/usr/bin/python3
import base64
coded_string = "d2lyZXNoYXJrLXN0dWRlbnRz="
base64.b64decode(coded_string)Let’s think about http, privacy, and security in various
scenarios:
https://www.eff.org/pages/tor-and-https
https://en.wikipedia.org/wiki/Reverse_proxy
Reverse proxy allows multiple HTTP endpoints (via more than
“Host:”),
at one IP/domain.
* [ ] expand on this maybe later.
https://en.wikipedia.org/wiki/Cross-origin_resource_sharing
Goal
Learn how to build client/server applications that communicate using
sockets.
Socket:
A tunnel between application processes, in an end-to-end transport
protocol
Two primary socket types for two transport services exist.
UDP is an unreliable, lightweight datagram
service.
TCP is a reliable, heavier, byte-stream, connection
oriented service.
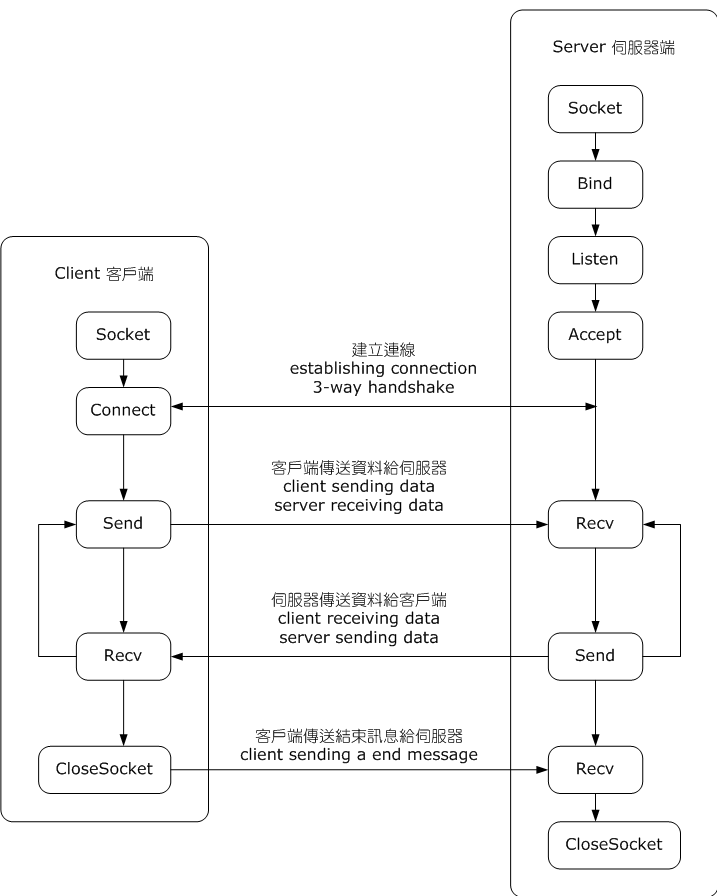
Application example we’ll put in code, in order:
Client inputs a line of characters (data) from the keyboard,
and
sends the data to server.
Server receives the data,
converts the characters to uppercase, and
sends the modified data to client.
Client receives modified data, and
displays it as a printed line on the screen
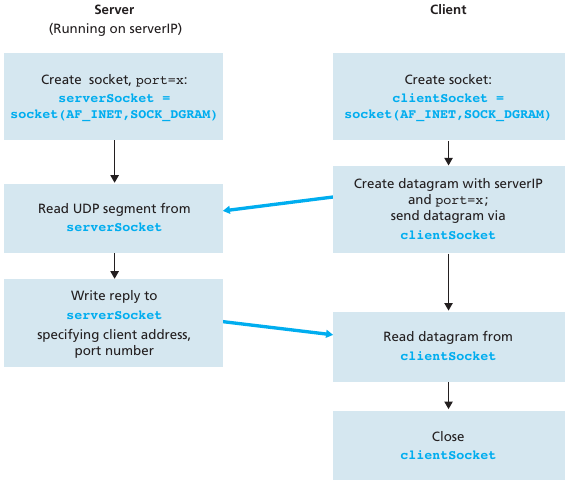
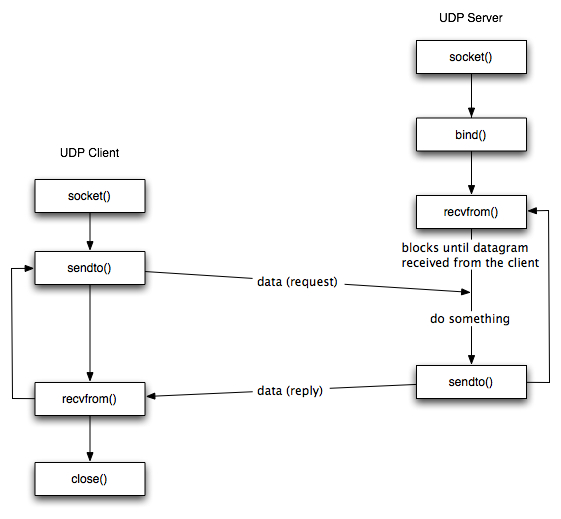
UDP involves no persistent “connection” between a client and
server.
No handshaking occurs before sending data.
A sender explicitly attaches a destination IP address and port number to
each packet.
A receiver extracts the sender’s IP address and port number from each
received packet.
Transmitted data may be lost.
Transmitted data may be received out-of-order.
UDP provides unreliable transfer of groups of bytes (“datagrams”)
between client and server.
UDP socket code:
02-Application/socket_01_UDP_server.py
02-Application/socket_01_UDP_client.py
Demonstrate:
0. Run in background:
python3 socket_01_UDP_server.py
Show Wireshark watching the client and server code:
sudo wireshark &
Connect with:
python3 socket_01_UDP_client.py
nc -uC 127.0.0.1 6789
man nc # ncat can send UDP packets too!Show how nc or multiple python clients can block
+++++++++++++++++++++++++++++++++ Cahoot-02-13
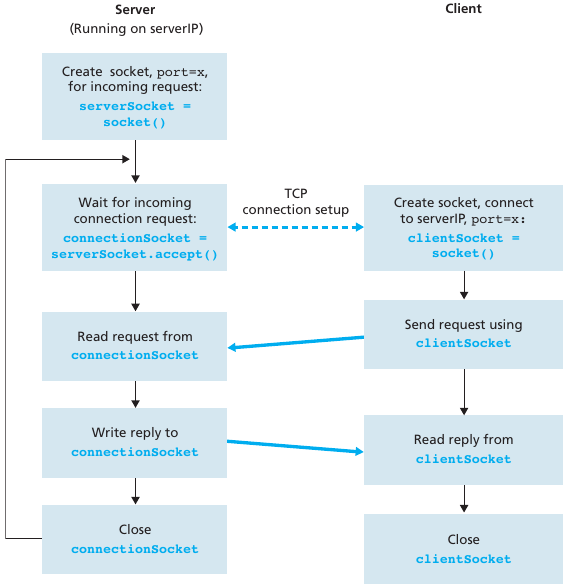
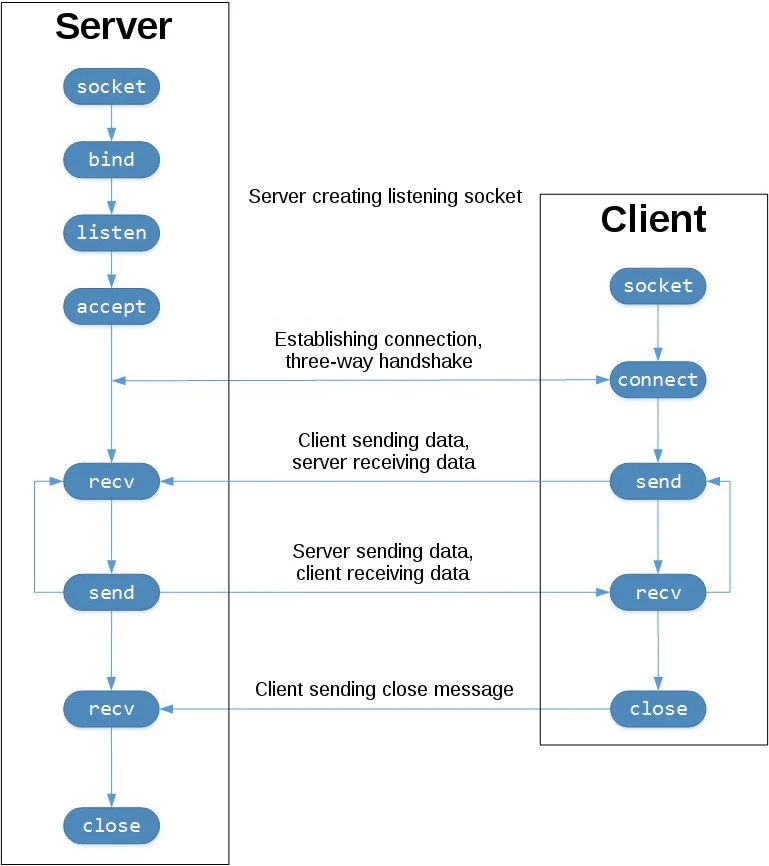
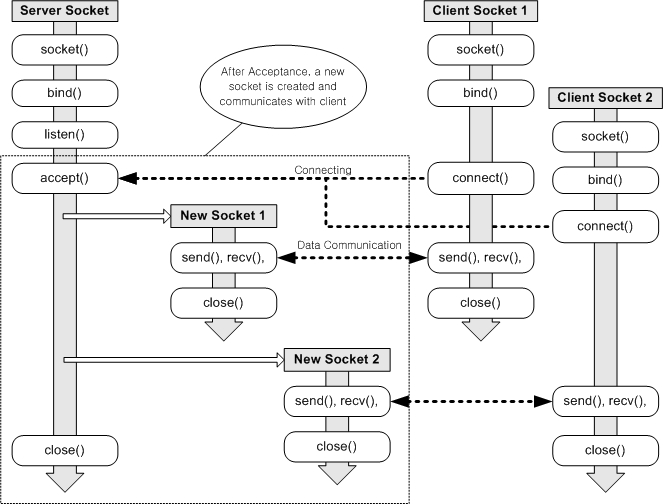
A server process must first be running.
The server must have created a TCP socket,
that welcomes a client’s contact.
A client contacts a server.
The client specifies an IP address and port number of a server
process.
The client uses that address to create a TCP socket.
The client’s TCP socket establishes a connection to the server.
When contacted by a client on the welcoming socket,
the server’s TCP socket creates a secondary new socket,
for the server process to communicate with that particular client.
This allows server to talk with multiple clients.
Source port numbers distinguish different clients.
TCP provides a reliable, in-order, byte-stream transfer between a client
and server.
TCP socket code:
Example 1:
02-Application/socket_02_TCP_server.py
02-Application/socket_02_TCP_client.py
Example 2:
02-Application/socket_02_TCP_server2.py
02-Application/socket_02_TCP_client2.py
Demonstrate:
0. Run a server:
python3 socket_02_TCP_server.py
Show Wireshark watching the client and server code:
sudo wireshark &
Connect with
python socket_02_TCP_client.py
nc -C 127.0.0.1 6789# new option
man ss
ss# old, ss is better
man netstat
netstat -an# another option
man lsof
lsof -i -n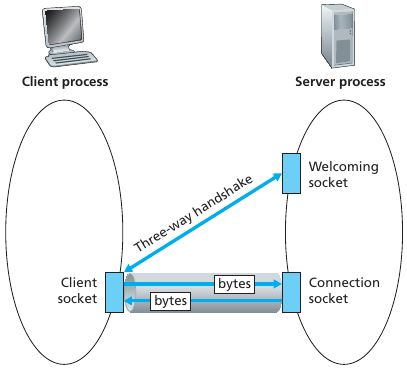
The term “port” is not the same idea or definition as the term
“socket”.
Socket is an instance object dually created both:
within a requesting application, and
within an operating system for that requesting application.
Port is a designation dually configured both:
as field in the transport-layer headers, in actual packets, and
in the OS’s kernel networking core, and firewall configuration.
The OS’s kernel routes packets to the application.
Step by step:
+++++++++++++++++++++++++++++++++ Cahoot-02-14
https://realpython.com/python-concurrency/
https://docs.python.org/3/c-api/init.html#thread-state-and-the-global-interpreter-lock
https://wiki.python.org/moin/GlobalInterpreterLock
https://realpython.com/python-gil/
Don’t like the GIL,
perhaps go with pypy:
https://www.pypy.org
https://realpython.com/pypy-faster-python/
You can use either:
multithreading
multiprocessing
asyncio
When should you use each?
multithreading to deal with simple blocking (no real speed up).
multiprocessing to run over multiple cores (speed up).
asyncio to deal more more complex or larger-scale needs (often
blocking).
https://www.geeksforgeeks.org/multiprocessing-python-set-1/
https://www.geeksforgeeks.org/multiprocessing-python-set-2/
https://www.geeksforgeeks.org/multithreading-python-set-1/
https://www.geeksforgeeks.org/multithreading-in-python-set-2-synchronization/
https://realpython.com/intro-to-python-threading/
See my code now:
02-Application/thread_00_none.py
02-Application/thread_01_unrolled.py
02-Application/thread_02_fake.py
02-Application/thread_03_storage.py
Show multi-threaded examples now:
02-Application/socket_04_TCP_server_mt.py
02-Application/socket_04_TCP_client_mt.py
Now, nc does not block the server from other
client’s:
python3 socket_04_TCP_server_mt.py &
nc -C 127.0.0.1 50002
python3 socket_04_TCP_server_mt.pyhttps://docs.python.org/3/library/socket.html
https://realpython.com/python-sockets/
Let’s review some program-internal functions.
>>> help(socket.socket.bind)
bind(...)
bind(address)
Bind the socket to a local address.
For IP sockets, the address is a pair (host, port);
the host must refer to the local host.
For raw packet sockets the address is a tuple
(ifname, proto [,pkttype [,hatype [,addr]]])socket.socket.bind takes a tuple: (hostname or IP,
port)
https://serverfault.com/questions/78048/whats-the-difference-between-ip-address-0-0-0-0-and-127-0-0-1
What are valid hostname or IP addresses to use?
The use of the term “local” above is ambiguous.
Q: What does it mean here, operationally?
A: That the IP address being bound is assigned to an interface managed
by your operating system!
More to come on interfaces when we cover the network layer:
04-NetworkData.html
""
defaults to all traffic to the machine.
It is the same as 0.0.0.0 for IPv4.
It’s easier for IPv6.
0.0.0.0
which also listens to all traffic on the machine
(0.0.0.0 means various different things in different contexts).
https://www.rfc-editor.org/rfc/rfc1122#page-29 section
3.2.1.3
(a) { 0, 0 }
This host on this network.
MUST NOT be sent,
except as a source address as part of an initialization procedure,
by which the host learns its own IP address.
See also Section 3.3.6 for a non-standard use of {0,0}.
https://www.rfc-editor.org/rfc/rfc5735#section-3
0.0.0.0/8 - Addresses in this block refer to source hosts on “this”
network.
Address 0.0.0.0/32 may be used as a source address for this host on this
network;
other addresses within 0.0.0.0/8 may be used to refer to specified hosts
on this network ([RFC1122], Section 3.2.1.3).
Despite the standard, 0.0.0.6 for example, won’t bind in python3.
<hostname>
https://docs.python.org/3/library/socket.html
If you use a hostname in the host portion of IPv4/v6 socket
address,
the program may show a nondeterministic behavior,
as Python uses the first address returned from the DNS resolution.
The socket address will be resolved differently into an actual IPv4/v6
address,
depending on the results from DNS resolution and/or the host
configuration.
For deterministic behavior use a numeric address in host portion.
On my Fedora machine, it resolves to 127.0.0.1.
Hostname is a shallow alias, implemented via checking:
/etc/hosts
127.0.0.1 through 127.255.255.254 (CIDER notation:
127.0.0.0/8)
https://www.rfc-editor.org/rfc/rfc5735#section-3
127.0.0.0/8 - This block is assigned for use as the Internet host
loopback address.
A datagram sent by a higher-level protocol to an address anywhere within
this block loops back inside the host.
This is ordinarily implemented using only 127.0.0.1/32 for
loopback.
As described in [RFC1122], Section 3.2.1.3,
addresses within the entire 127.0.0.0/8 block do not legitimately appear
on any network anywhere.
Your local machine only.
You can use 127.0.0.4 (or whatever in the range),
but that socket will only be reachable on that IP.
Python’s sending socket defaults to 127.0.0.1 as the sending IP,
when sending to any localhost address.
A LAN-only IP address
10.0.0.0 - 10.255.255.255 (10.0.0.0/8 prefix)
172.16.0.0 - 172.31.255.255 (172.16.0.0/12 prefix)
192.168.0.0 - 192.168.255.255 (192.168.0.0/16 prefix)
https://datatracker.ietf.org/doc/html/rfc1918
These IP ranges are declared as LAN IPs,
as opposed to public, globally routable IPs,
or to localhost IPs, etc.
If you have an interface bound to an IP in this range,
then you could bind any of these.
If your interface in the OS is not bound to one,
then you can not bind the socket in python either.
A public, globally routable IP address
More-or-less anything not in the below list:
https://www.iana.org/assignments/iana-ipv4-special-registry/iana-ipv4-special-registry.xhtml
https://en.wikipedia.org/wiki/IPv4#Special-use_addresses
If you have an interface bound to an IP in this range,
then you could bind any of these.
If your interface in the OS is not bound to one,
then you can not bind the socket in python either.
Which should you choose?
If you’re debugging locally,
then use 127.0.0.1.
If you are lazy,
then use “” or 0.0.0.0
If you want more security,
then consider using a specific IP,
of an interface on your machine.
Below, we illustrate state diagrams for UDP and TCP sockets.
These are standard POSIX sockets,
also known as BSD or Berkeley sockets.
https://en.wikipedia.org/wiki/Berkeley_sockets
Many languages use similar BSD sockets to those in the C language.
Python’s also follow the below API.
Discussion question:
What is the value of having a POSIX standard?
What is the value of specifying the socket API itself as part of
POSIX?
https://en.wikipedia.org/wiki/POSIX
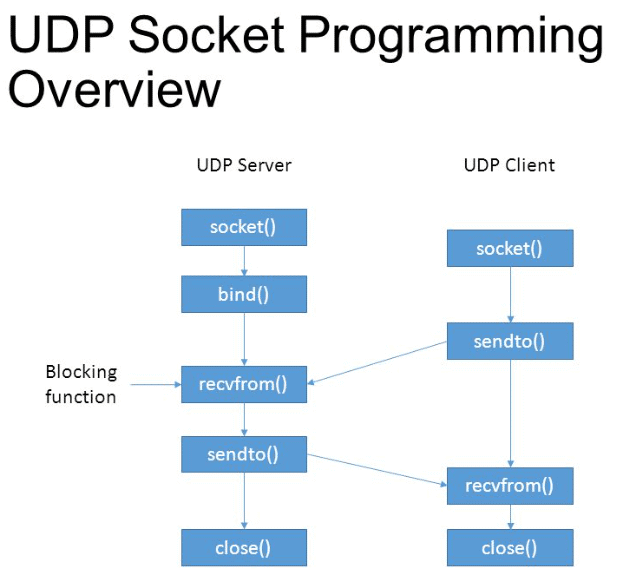
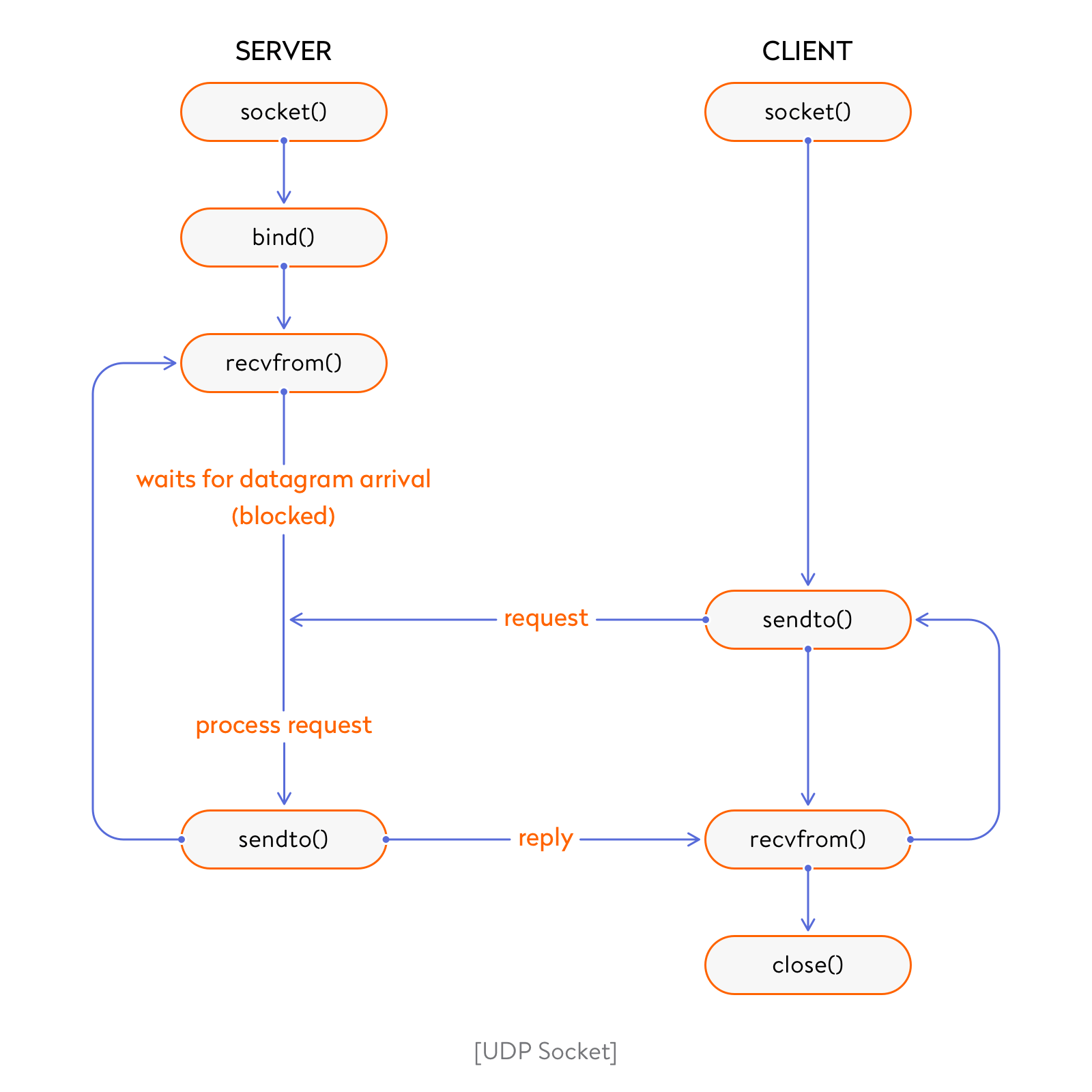
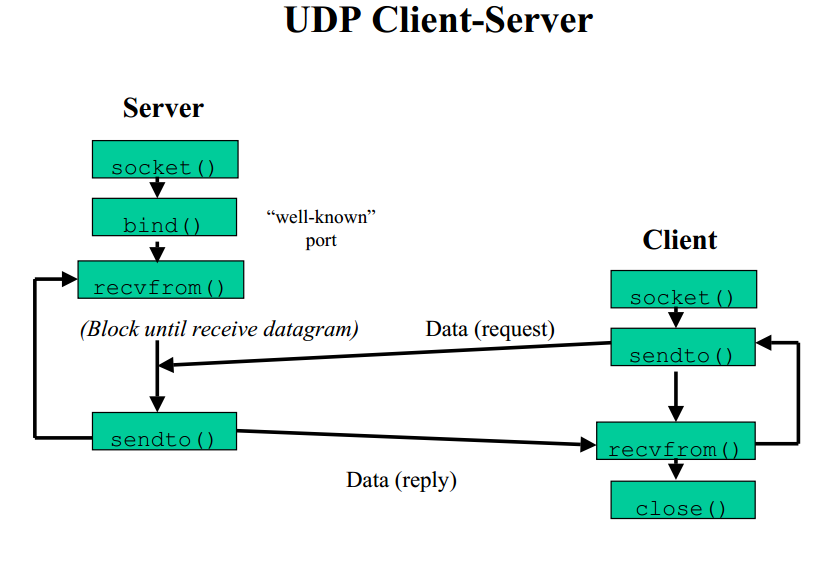
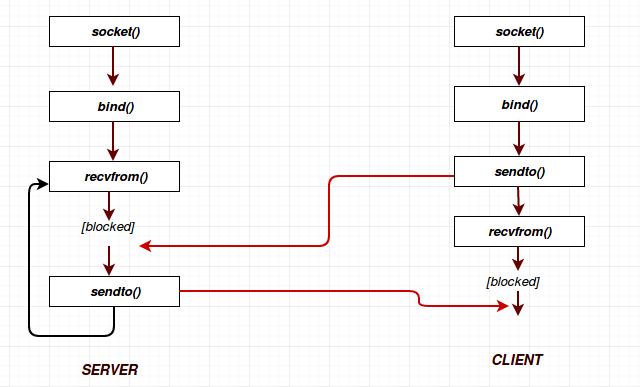
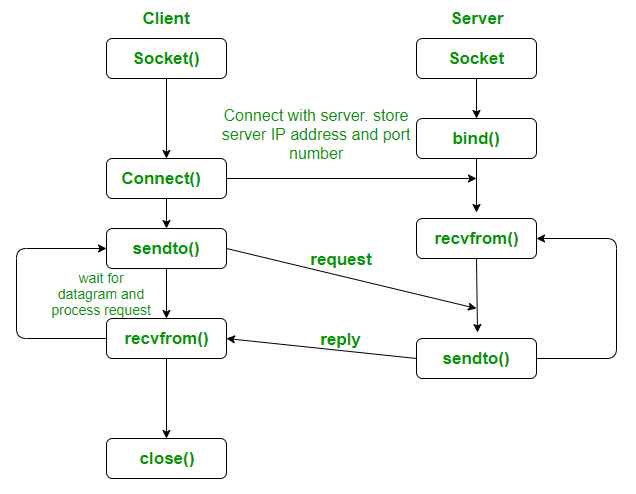
The overview
The states:
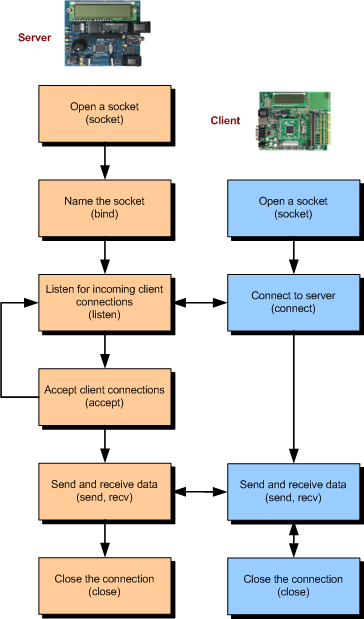
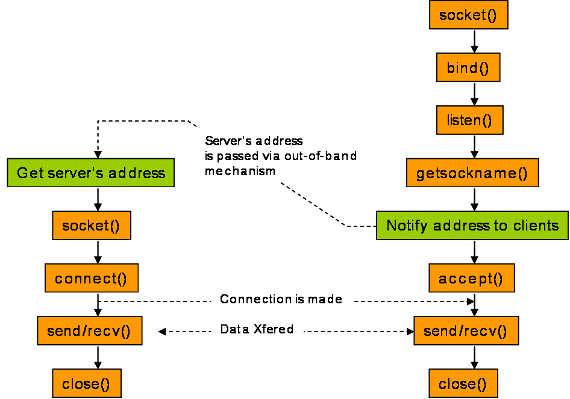
To think ahead to what we’re covering next,
TCP’s actual internal FSM is much more detailed than this!
These images below are just the high-level API.
File Transfer Protocol
https://en.wikipedia.org/wiki/File_Transfer_Protocol
https://tools.ietf.org/html/rfc2428
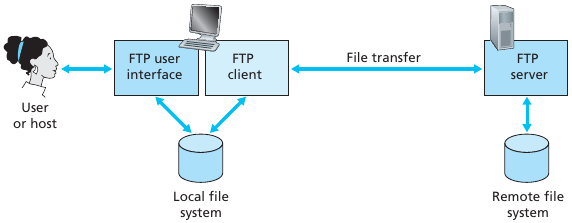
FTP client contacts FTP server at port 21, using TCP.
Client authorized over control connection.
Client browses remote directory, sends commands over control
connection.
When server receives file transfer command, server opens 2nd TCP data
connection (for file) to client.
After transferring one file, server closes data connection.
Server opens another TCP data connection to transfer another file.
Control connection: “out of band”.
FTP server maintains “state”: current directory, earlier
authentication.
FTP control and data connections
FTP uses two parallel TCP connections to transfer a file, a control
connection and a data connection.
The control connection is used for sending control
information between the two hosts,
information such as user identification, password, commands to change
remote directory,
and commands to “put” and “get” files.
The data connection is used to actually send a
file.
FTP is said to send its control information
out-of-band.
HTTP sends request and response header lines into the same TCP
connection that carries the transferred file itself,
named in-band.

FTP sequence
When a user starts an FTP session with a remote host,
the client side of FTP (user) first initiates a control TCP connection
with the server side (remote host) on server port number 21.
Client side of FTP sends the user identification and password over this
control connection.
Client side of FTP also sends, over the control connection, commands to
change the remote directory.
When the server side receives a command for a file transfer over the
control connection (either to, or from, the remote host),
the server side initiates a TCP data connection to the client
side.
FTP sends exactly one file over the data connection and then closes the
data connection.
If, during the same session, the user wants to transfer another
file,
then FTP opens another data connection.
Control connection remains open throughout the duration of the user
session,
but a new data connection is created for each file transferred within a
session
(data connections are non-persistent).
FTP requests
Commands, from client to server, and replies, from server to client, are
sent across the control connection in 7-bit ASCII format.
In order to delineate successive commands, a carriage
return and line feed end each command.
Each command consists of four uppercase ASCII characters, some with
optional arguments:
USER username: Used to send the user identification to the server.
PASS password: Used to send the user password to the server.
LIST: Used to ask the server to send back a list of all the files in the current remote directory. The list of files is sent over a (new and non-persistent) data connection rather than the control TCP connection.
RETR filename: Used to retrieve (that is, get) a file from the current directory of the remote host. This command causes the remote host to initiate a data connection and to send the requested file over the data connection.
STOR filename: Used to store (that is, put) a file into the current directory of the remote host.
FTP replies Some typical replies, along with their possible messages, are as follows:
331 Username OK, password required
125 Data connection already open; transfer starting
425 Can’t open data connection
452 Error writing file
Demonstrate:
[ ] Find an open ftp site, watch connection with wireshark
With sftp, do we see any application layer protocol details with
Wireshark?
https://www.computer-networking.info/1st/html/application/email.html
https://www.computer-networking.info/2nd/html/protocols/email.html
https://tools.ietf.org/html/rfc5321 (SMTP)
https://en.wikipedia.org/wiki/Simple_Mail_Transfer_Protocol
https://tools.ietf.org/html/rfc1939 (POP3)
https://en.wikipedia.org/wiki/Post_Office_Protocol
https://tools.ietf.org/html/rfc3501 (IMAP)
https://en.wikipedia.org/wiki/Internet_Message_Access_Protocol
Three major components:
1. user agents
2. mail servers
3. simple mail transfer protocol: SMTP
User Agent
a.k.a. “mail reader”
For composing, editing, reading mail messages.
e.g., Thunderbird, K9, Outlook, Kmail, iPhone mail client, etc.
Outgoing and incoming messages can be stored on server.
Mail servers:
Mailbox contains incoming messages for user.
Message queue of outgoing (to be sent) mail messages.
SMTP protocol between mail servers to send email messages, with each
entity:
client: sending mail server
server: receiving mail server
Observe SMTP with wireshark (does any of this show in wireshark)
ncat -C smtp.zoho.com 587Does any of the application layer information show in wireshark
here?
ncat --ssl -C smtp.zoho.com 465
HELO web.site, MAIL FROM, RCPT TO, DATA, QUIT
Observe POP
ncat --ssl -C pop.zoho.com 995
user bob
pass password
list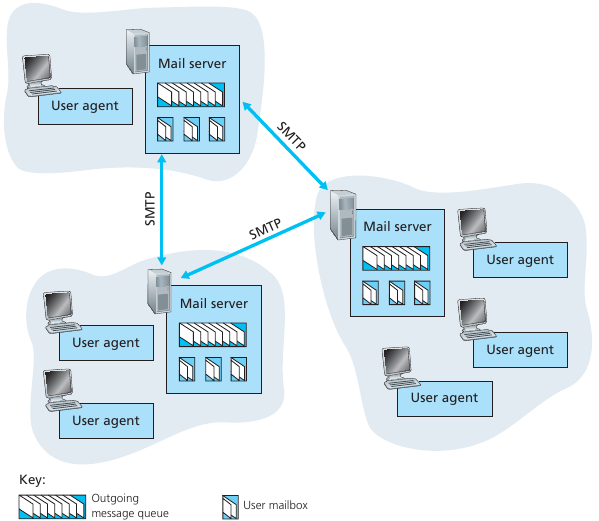
User-agent is local, but also remote.
User-agent used to be on remote machine.
Then, real mail user-agents were used.
Then user-agent moved back onto remote machines.
Mail server is a messy multi-part aggregate of things in software.
How many people still use a real, local, MUA?
Electronic Mail: SMTP
[RFC 2821]
Alice sends a message to Bob
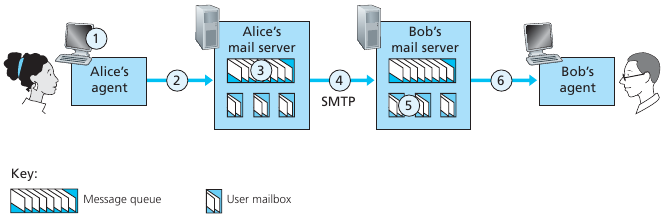
Basic process
Example SMTP transcript
Hostname of the client is crepes.fr
Hostname of the server is server.edu
S: 220 server.edu
C: EHLO crepes.fr // a nicer HELO
S: 250 Hello crepes.fr, pleased to meet you
C: MAIL FROM: <alice@crepes.fr>
S: 250 alice@crepes.fr ... Sender ok
C: RCPT TO: <bob@server.edu>
S: 250 bob@server.edu ... Recipient ok
C: DATA
S: 354 Enter mail, end with "." on a line by itself
C: Do you like ketchup?
C: How about pickles?
C: .
S: 250 Message accepted for delivery
C: QUIT
S: 221 server.edu closing connectionAnother SMTP example
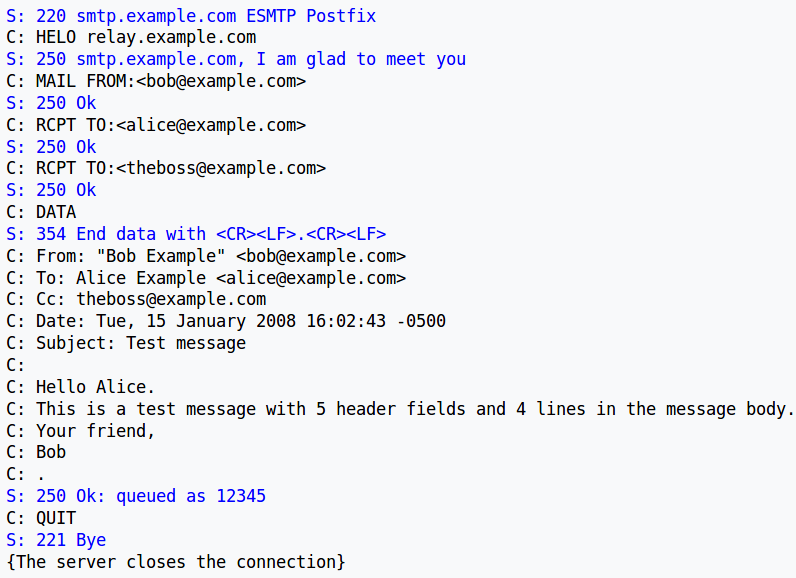
base64 encoding is required for username and password:
https://en.wikipedia.org/wiki/Base64
c: AUTH LOGIN
s: 334 VXNlcm5hbWU6
c: yourusernameinb64encoding
s: 334 VXNlcm5hbWU6
c: yourpasswordinb64encodingTo get base64 encoding of a string:
# encode in bash
$ echo -n 'string' | base64
# decode in bash
$ echo -n c3RyaW5nCg== | base64 -d# In python:
>>> import base64
>>> base64.b64encode('string'.encode())
>>> base64.b64decode('c3RyaW5n')then, you can proceed sending:
C: MAIL FROM: <alice@crepes.fr>
S: 250 alice@crepes.fr ... Sender ok
C: RCPT TO: <bob@server.edu>
S: 250 bob@server.edu ... Recipient ok
C: DATA
S: 354 Enter mail, end with "." on a line by itself
C: Do you like ketchup?
C: How about pickles?
C: .
S: 250 Message accepted for delivery
C: QUIT
S: 221 server.edu closing connectionSMTP uses persistent connections
SMTP requires message (header and body) to be in 7-bit ASCII
SMTP server uses CRLF.CRLF to determine end of message
Comparison with HTTP:
Message header
From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Searching for the meaning of life.Show: Open an email in Mutt/raw to illustrate headers, MIME, multipart
Email protocols and direction of communication
When sent an email by Alice, how does a recipient like Bob, running a
user agent on his local PC, obtain his messages, which are sitting in a
mail server within Bob’s mail provider?

* Post Office Protocol—Version 3 (POP3)
* Internet Mail Access Protocol (IMAP)
* HTTP
C: client
S: serverncat mailServer 110
S: +OK POP3 server ready
C: user bob
S: +OK
C: pass hungry
S: +OK user successfully logged onC: list
S: 1 498
S: 2 912
S: .
C: retr 1
S: (blah blah ...
S: .................
S: ..........blah)
S: .
C: dele 1
C: retr 2
S: (blah blah ...
S: .................
S: ..........blah)
S: .
C: dele 2
C: quit
S: +OK POP3 server signing offAnother POP3 example
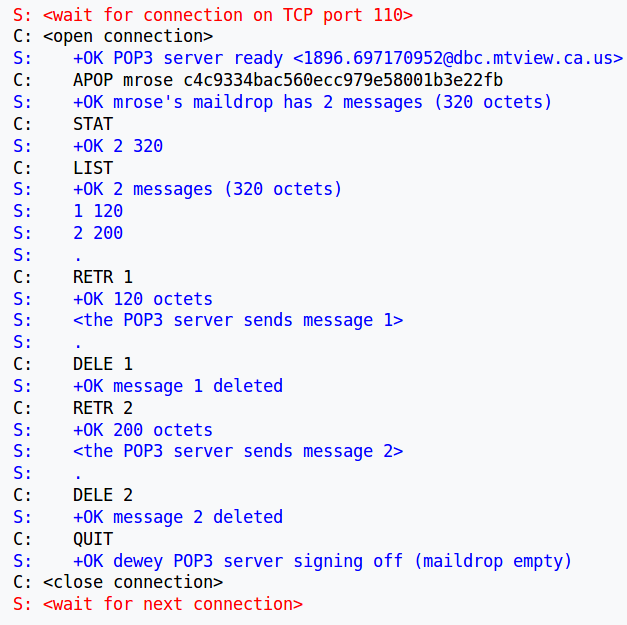
++++++++++++++ Cahoot-02-6
Discussion question:
At first guess, would you think the internet has a kill-switch, like it
might in a Hollywood movie?
If it did, what might the consequences be?
On businesses?
On people?
In the USA?
In China?
In Russia?
In Kazakhstan?
etc.
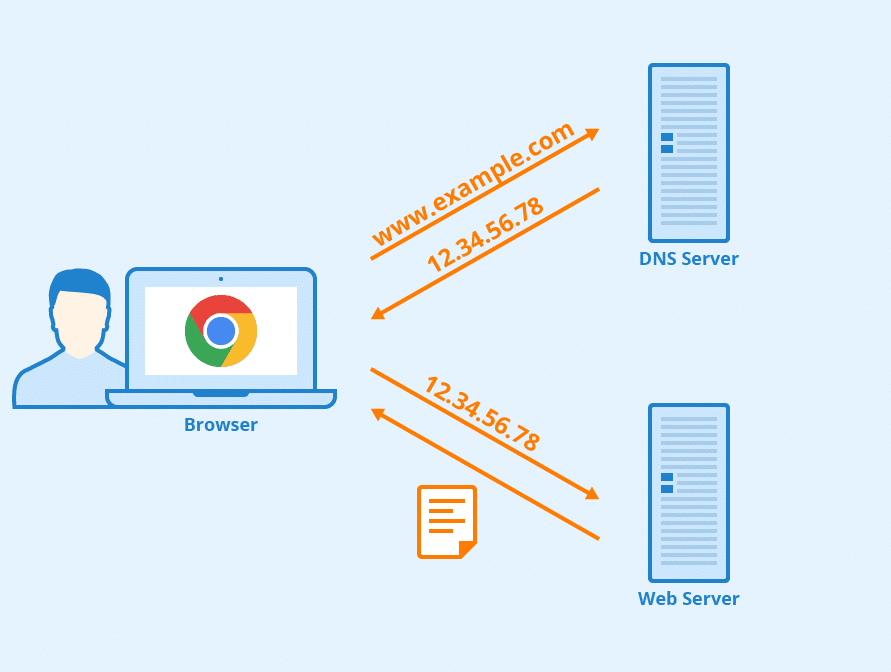
“The Domain Name Server (DNS) is the Achilles heel of the
Web.
The important thing is that it’s managed
responsibly.”
-Tim Berners-Lee
People: many identifiers:
Internet hosts, routers:
The big questions:
(double-meaning intended)
Web browser example:
<https://www.someschool.edu>, from a URL entered by
the user, and passes the hostname to the client side of the DNS
application.Domain Name System:
Discussion Question:
What are several reasons an entity might want to steal a network
name?
Would you guess that all such purposes bad?
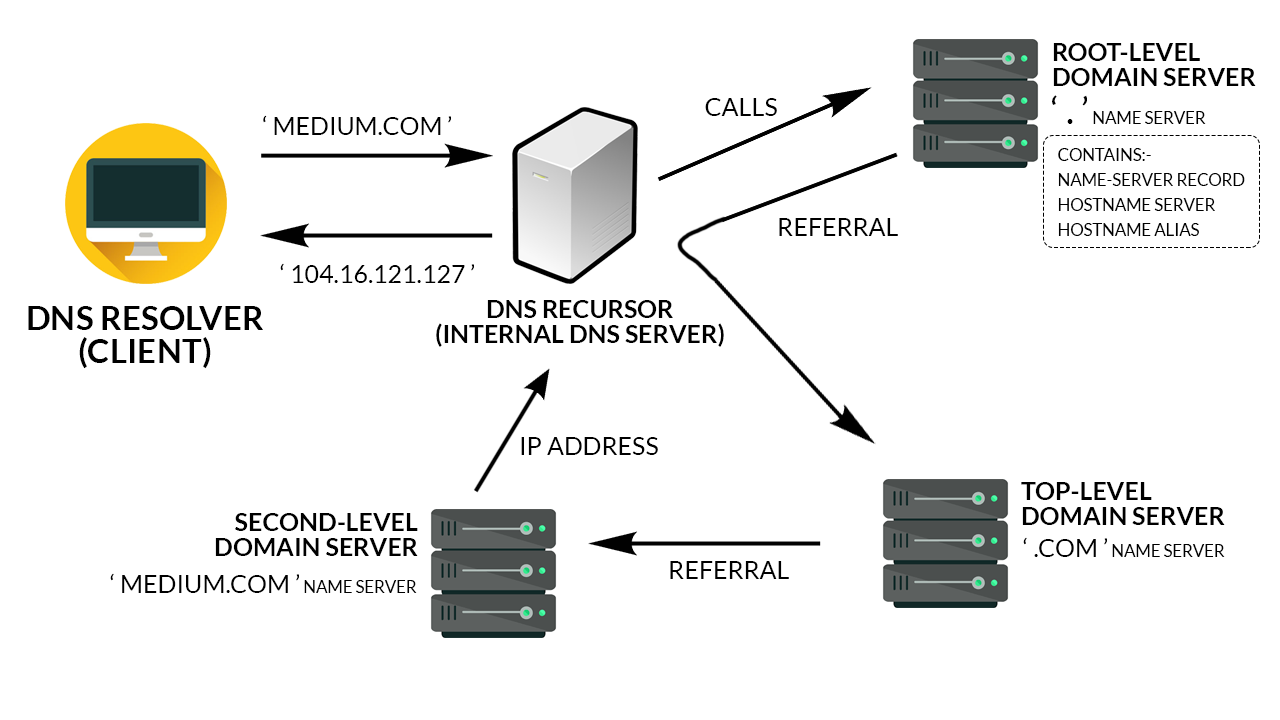
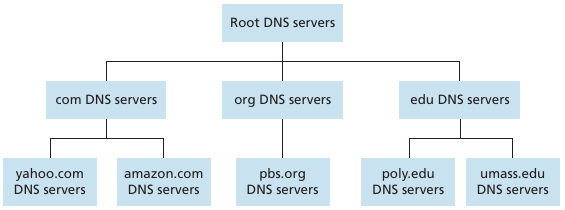
DNS is just a pyramid scheme…
client wants IP for <https://www.amazon.com>; 1st
approximation:
<https://www.amazon.com>https://en.wikipedia.org/wiki/Root_name_server
https://en.wikipedia.org/wiki/DNS_root_zone
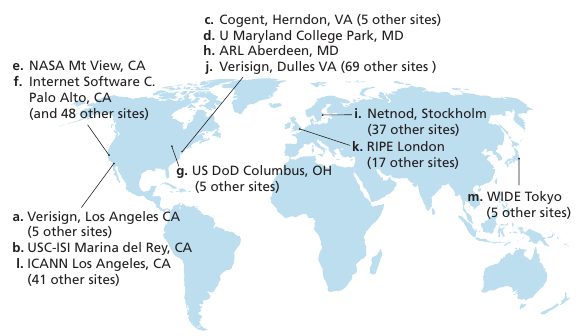
https://en.wikipedia.org/wiki/Top-level_domain
If https://mst.eu is
available…
What fun things could we do with that…?
Ask: How can one “be” an EU resident on the internet?
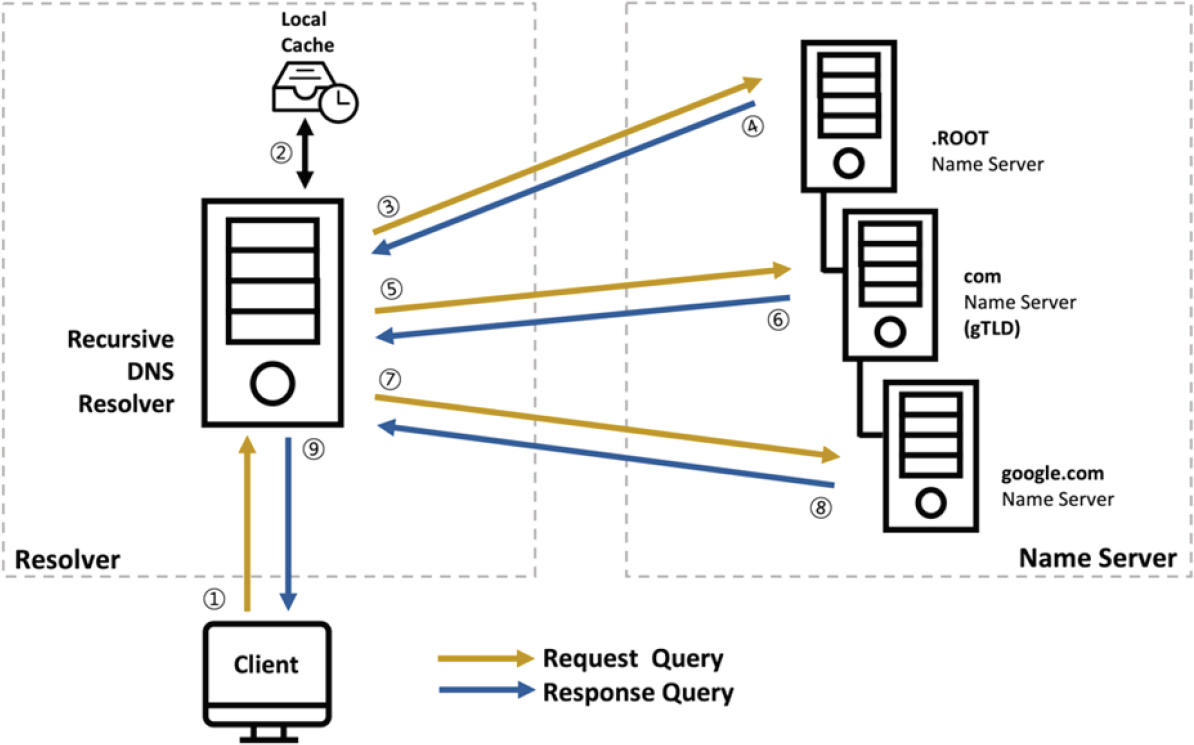
Show: some Wireshark observations of nslookup for various types of record (overview this time, more detail again lower).
Visit https://mst.edu with web browser
Make a manual query using command line tools
#!/bin/bash
nslookup mst.edu
nslookup www.mst.edu
dig mst.edu
dig www.mst.edu
whois mst.edu
whois icann.org
# What are the authoritative servers?
nslookup -type=NS mst.edu
# What do the authoritative servers say?
nslookup mst.edu ns-1.mst.eduhttps://en.wikipedia.org/wiki/WHOIS
WHOIS going to tell us a Domain Name joke?
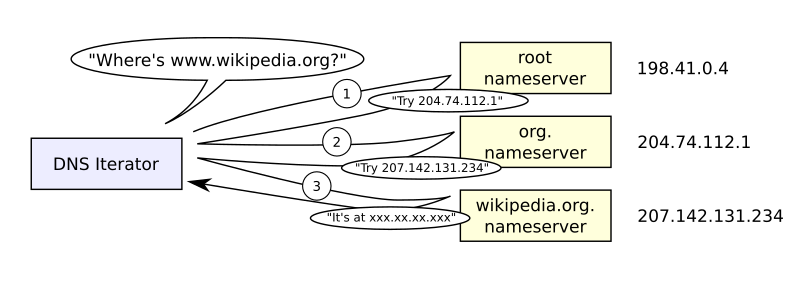
Standard iterated query
Some host at cis.poly.edu wants IP address for
gaia.cs.umass.edu
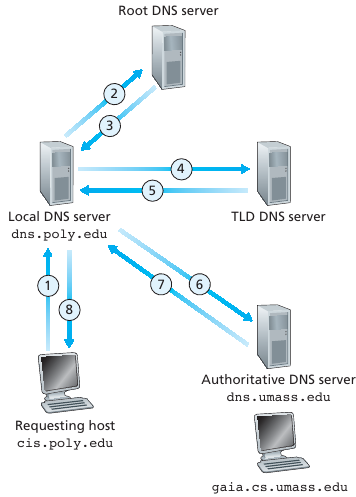
Iterated query:
Contacted server replies with name of server to contact.
“I don’t know this name,
but ask this other server who is responsible for knowing,
or is responsible for asking some server that is.”
Recursive queries
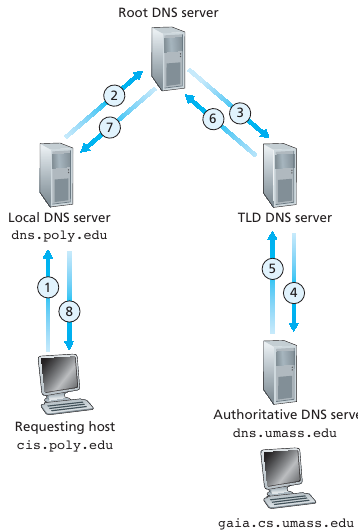
Recursive query:
Puts burden of name resolution on contacted name server.
Heavy load at upper levels of hierarchy?
Q:
Can one’s own machine just do the query to root, TLD, and
authoritative?
Why bother with the institutional resolver?
A:
Yes, if you set up your own DNS server (easy).
Just install bind, and configure it.
It’s just extra functionality not built into every client.
++++++++++++++ Cahoot-02-7
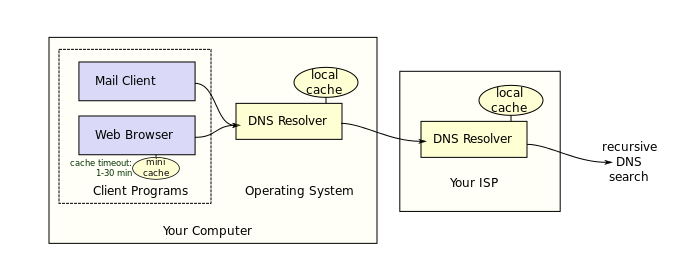
DNS caching, updating records
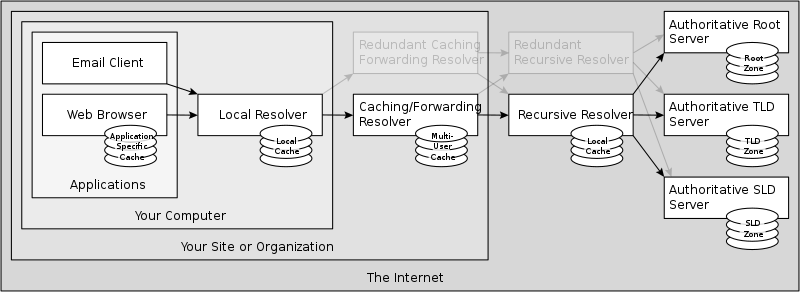
DNS is at the root of many internet problems…
https://en.wikipedia.org/wiki/Domain_Name_System#DNS_message_format
Query and reply messages, both with same overall message format
Message header
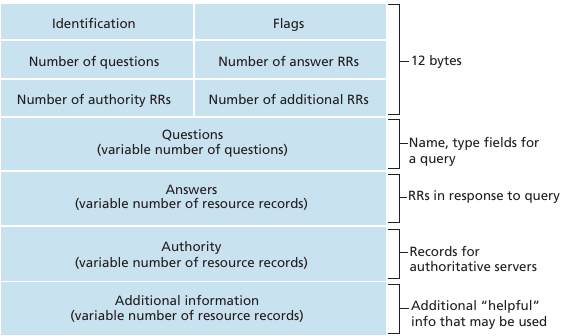
The header of DNS messages is composed of 12 bytes and its structure is shown in the figure below.

The QR flag is set to 0 in DNS queries and 1 in DNS answers.
The Opcode is used to specify the type of
query.
For instance, a standard query is when a client sends a name, and the
server returns the corresponding data.
An update request is when the client sends a name, and new data, and the
server then updates its database.
The AA bit is set, when the server that sent the
response has authority for the domain name found in the question
section.
In the original DNS deployments, two types of servers were considered :
authoritative servers and non-authoritative servers.
The authoritative servers are managed by the system administrators
responsible for a given domain.
They always store the most recent information about a domain.
Non-authoritative servers are servers or resolvers that store DNS
information about external domains without being managed by the owners
of a domain.
They may thus provide answers that are out of date.
From a security point of view, the authoritative bit is not an absolute
indication about the validity of an answer.
Ask: Is this secure?
It uses UDP; what does this imply?
Where TC is set, the partial RRSet that would not
completely fit may be left in the response.
When a DNS client receives a reply with TC set, it should ignore that
response, and query again, using a mechanism, such as a TCP connection,
that will permit larger replies.
The RD (recursion desired) bit is set by a client
when it sends a query to a resolver.
Such a query is said to be recursive because the resolver will recurse
through the DNS hierarchy to retrieve the answer on behalf of the
client.
In the past, all resolvers were configured to perform recursive queries
on behalf of any Internet host.
However, this exposes the resolvers to several security risks.
The simplest one is that the resolver could become overloaded by having
too many recursive queries to process.
As of this writing, most resolvers only allow recursive queries from
clients belonging to their company or network and discard all other
recursive queries.
The RA bit indicates whether the server supports recursion.
The RCODE is used to distinguish between different types of errors. See RFC 1035 for additional details.
The last four fields indicate the size of the Question, Answer, Authority and Additional sections of the DNS message.
The last four sections of the DNS message contain Resource Records (RR).
All RRs have the same top level format shown in the figure below.
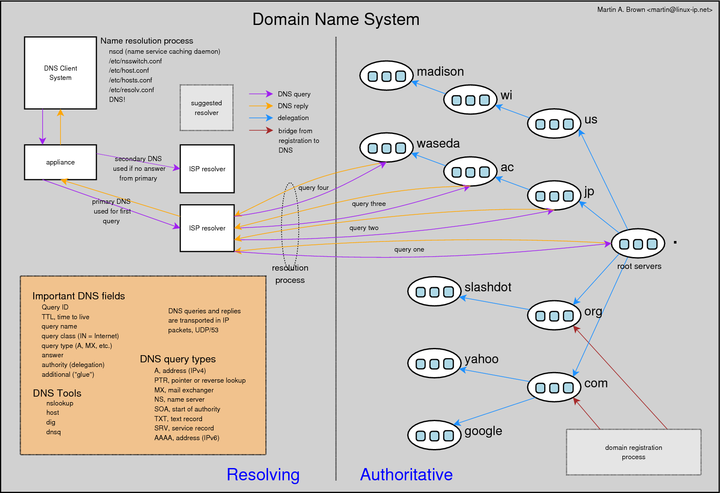
DNS: distributed database storing resource records (RR)
RR format: (name, value, type, ttl)
NAME
TYPE
CLASS
TTL
RDLENGTH
RDATA

Name indicates the name of the node to which this resource record pertains.
The two bytes Type field indicates the type of resource record.
The Class field was used to support the utilization of the DNS in other environments than the Internet.
The TTL field indicates the lifetime of the Resource
Record in seconds.
This field is set by the server that returns an answer and indicates for
how long a client or a resolver can store the Resource Record inside its
cache.
A long TTL indicates a stable RR.
Some companies use short TTL values for mobile hosts and also for
popular servers.
For example, a web hosting company that wants to spread the load over a
pool of hundred servers can configure its nameservers to return
different answers to different clients.
If each answer has a small TTL, the clients will be forced to send DNS
queries regularly.
The nameserver will reply to these queries by supplying the address of
the less loaded server.
The RDLength field is the length of the RData field that contains the information of the type specified in the Type field.
Several types of DNS RR are used in practice.
type=A
type=NS
type=CNAME
<https://servereast.backup2.ibm.com><https://www.example.com> could be a
CNAME for pc12.example.com that is the actual name of the server on
which the web server for <https://www.example.com>
runs.type=MX
There are more record types (summary of commonly
used):
https://en.wikipedia.org/wiki/List_of_DNS_record_types
+++++++++++++++++ Cahoot-02-8
Show: some Wireshark observations of nslookup for various types of record, this time in detail about the fields.
Visit https://mst.edu with web browser
Make a manual query using command line tools
#!/bin/bash
nslookup mst.edu
nslookup www.mst.edu
dig mst.edu
dig www.mst.edu
whois mst.edu
whois icann.org
# What are the authoritative servers?
nslookup -type=NS mst.edu
# What do the authoritative servers say?
nslookup mst.edu ns-1.mst.edu<https://www.networkuptopia.com>;
<networkutopia.com>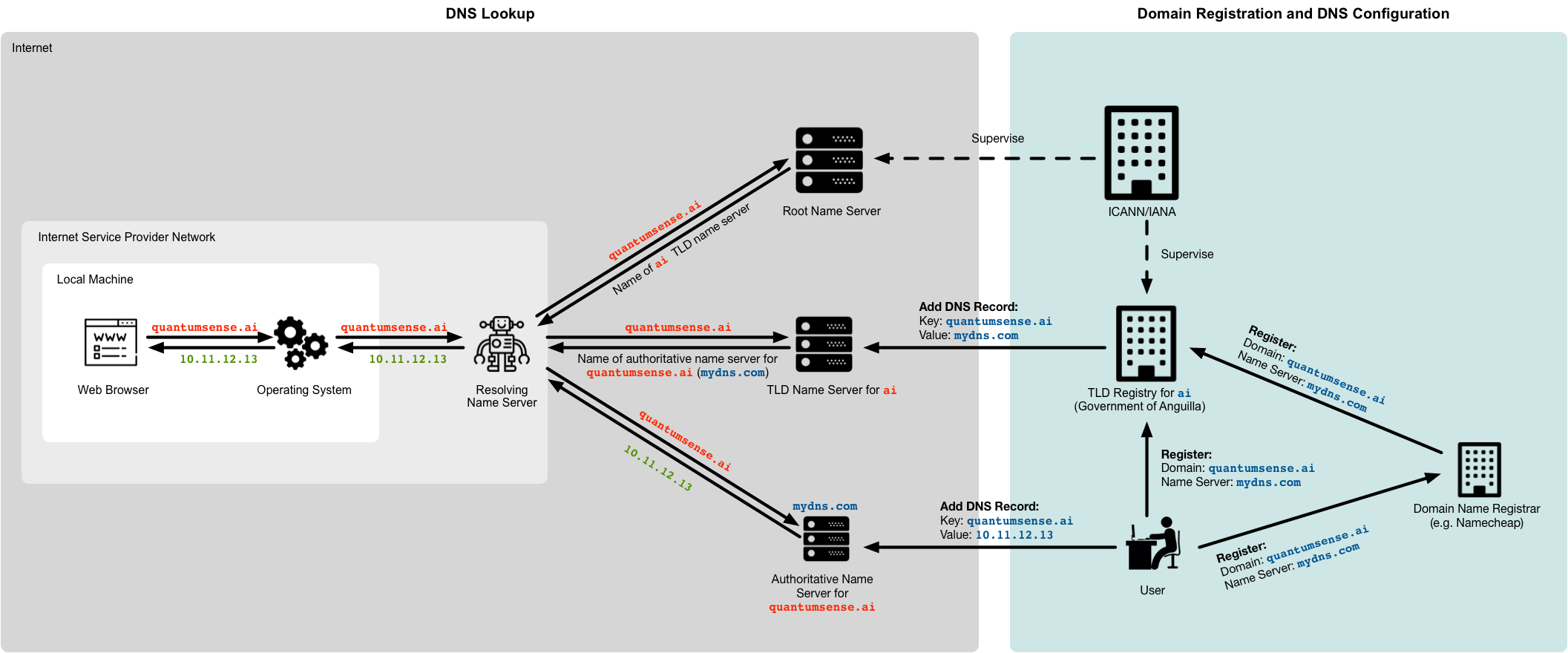
https://en.wikipedia.org/wiki/Reverse_DNS_lookup
https://en.wikipedia.org/wiki/Domain_Name_System#Security_issues
https://en.wikipedia.org/wiki/Domain_Name_System#Privacy_and_tracking_issues
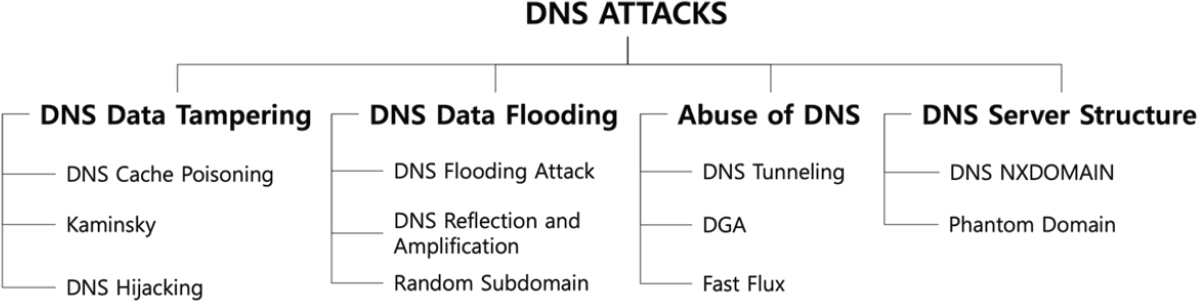
DDoS bandwidth-flooding attack
An attacker could attempt to send to each DNS root server a deluge of
packets,
so many that the majority of legitimate DNS queries never get
answered.
Bombard root servers with traffic.
This has not really been successful to date.
Defenses include:
Traffic filtering.
Local DNS servers cache IPs of TLD servers,
allowing root server bypass.
Bombarding TLD servers is potentially more dangerous.
Man-in-the-middle attack
The attacker intercepts queries from hosts and returns bogus
replies.
https://en.wikipedia.org/wiki/DNS_hijacking
(show in class)
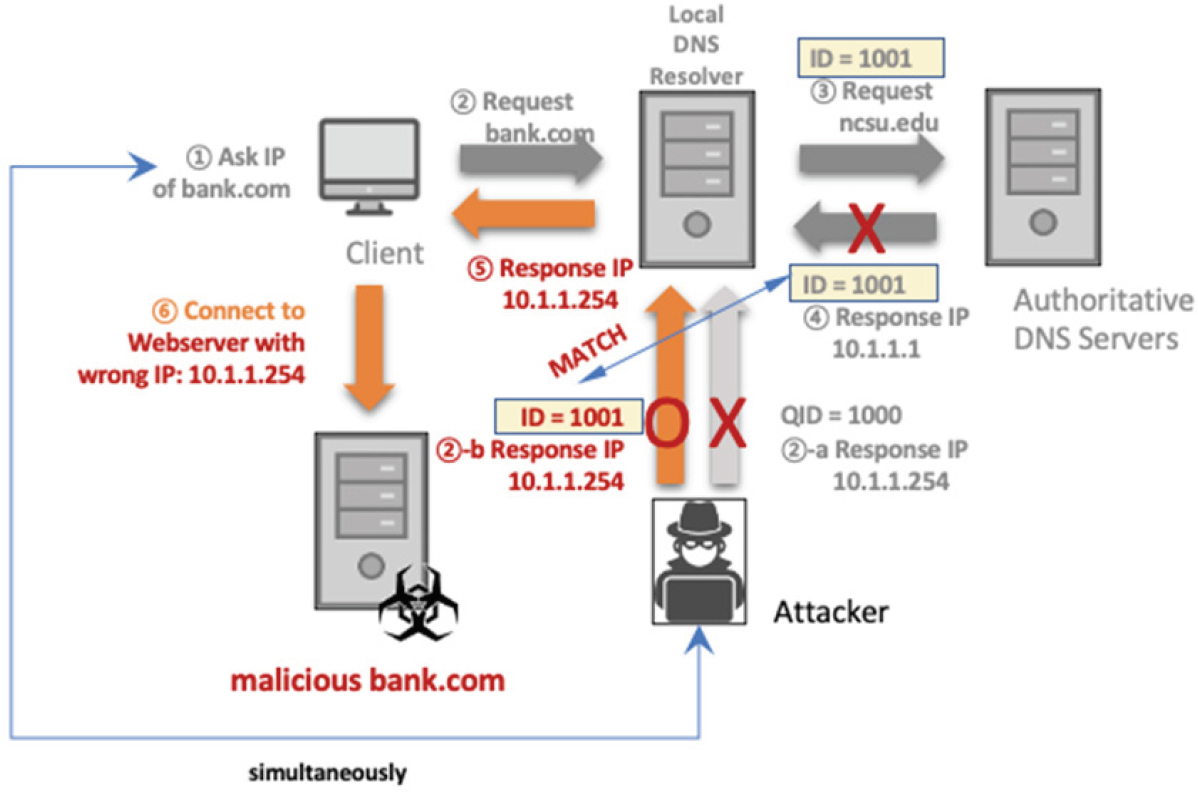
DNS poisoning attack
The attacker sends bogus replies to a DNS server,
who is making outgoing requests itself,
tricking the server into accepting bogus records into its cache.
Send bogus replies to DNS server, which caches
https://en.wikipedia.org/wiki/DNS_spoofing
(show in class)
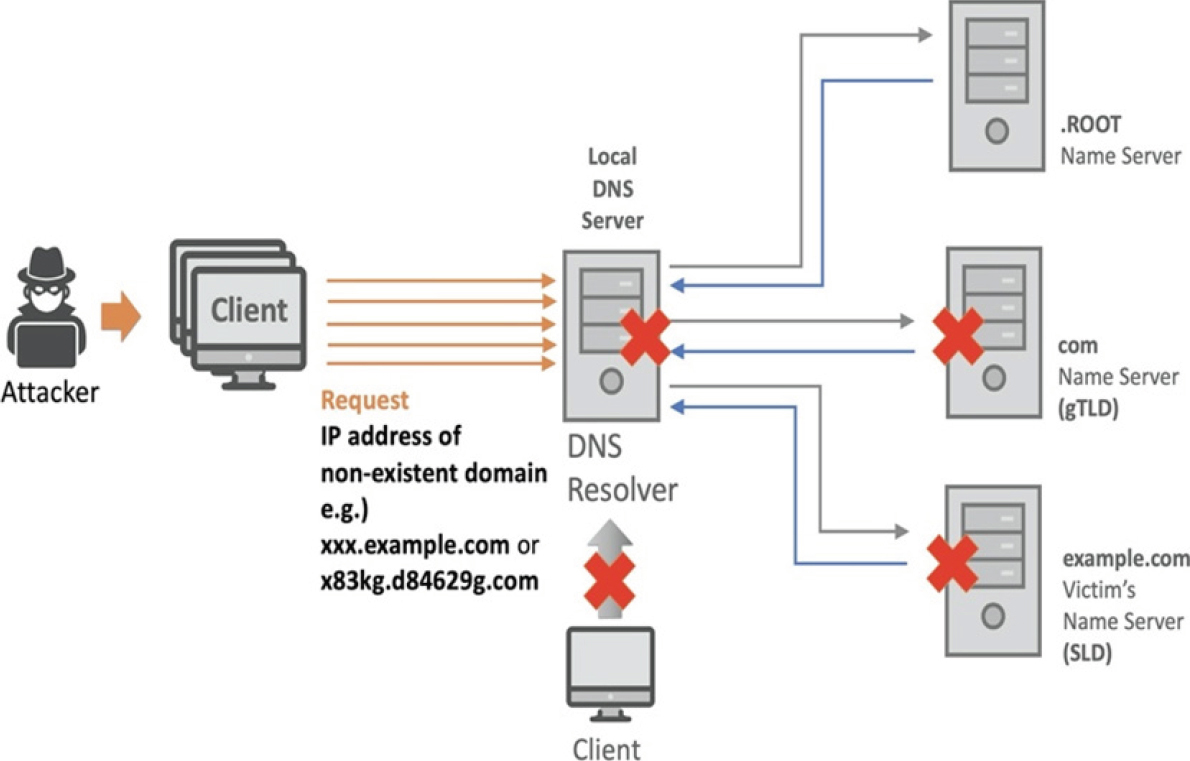
DNS redirection
Another important DNS attack is not an attack on the DNS service, per
se,
but instead exploits the DNS infrastructure,
to launch a DDoS attack against a targeted host.
Attacker sends DNS queries to many authoritative DNS servers,
with each query having the spoofed source address of the targeted
host.
The DNS servers then send their replies directly to the targeted
host.
Exploit DNS for DDoS:
send queries with spoofed source address and target IP.
This often requires amplification
DNS as exfiltration / infiltration / tunneling
One can sneak data through DNS requests or replies.
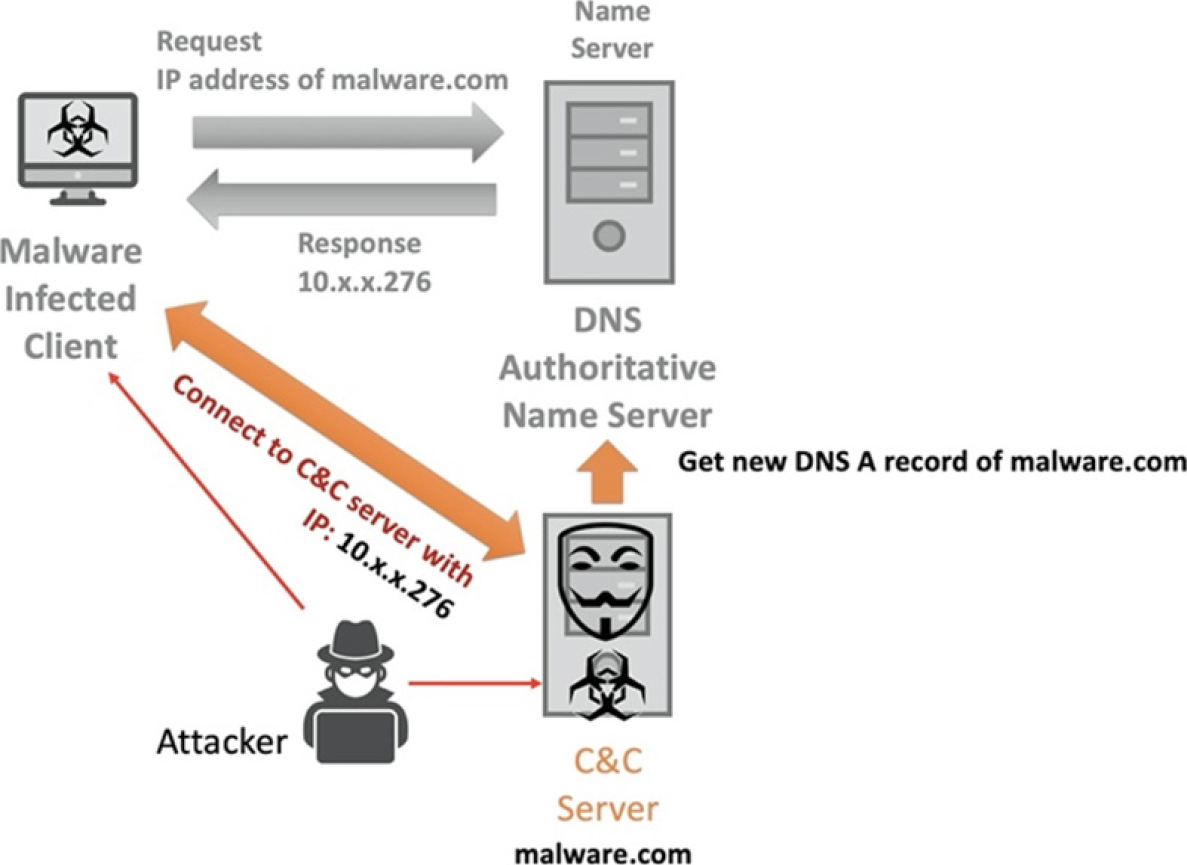
+++++++++++++++++ Cahoot-02-9
Ways to avoid those attacks:
Just encrypt the connections to the server:
https://en.wikipedia.org/wiki/DNS_over_HTTPS
https://en.wikipedia.org/wiki/DNS_over_TLS
Tor/VPN/Proxy (privacy, but also some security).
Cryptographic signatures on DNS messages
https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions
https://en.wikipedia.org/wiki/DNS-based_Authentication_of_Named_Entities
https://en.wikipedia.org/wiki/DNS_Certification_Authority_Authorization
The Lord of the DNS
One DNS to rule them all,
One DNS to find them,
One DNS to bring them all,
and in the darkness bind them…

(i.e., a big boring Sauron committee…)
https://en.wikipedia.org/wiki/ICANN
https://en.wikipedia.org/wiki/ICANN#Criticism
https://en.wikipedia.org/wiki/Internet_Assigned_Numbers_Authority
https://en.wikipedia.org/wiki/OpenNIC
(permitted to be an open alternative)
+++++++++++++++++ Cahoot-02-10
Fellowship of the DNS…
Fair, robust, distributed, decentralized, non-exploitable name
resolution,
is a bit of a:
https://en.wikipedia.org/wiki/Catch-22_(logic)
and a real difficult problem to solve…
Discussion question:
What might a reliable distributed solution look like?
Might they come with their own exploits and problems?
Might a p2p system end up even more dictatorially problematic than
DNS?
(e.g., Mr. Robot’s Evil Corp cryptocurrency)?
GNU name system
https://gnunet.org/gns
https://lsd.gnunet.org/lsd0001/
https://news.ycombinator.com/item?id=30154830
(discuss proposal to replace DNS!)
ICANN
https://icann.zoom.us/rec/play/znYwyZWPwrNraKqiZCLwOkHp_NITBj0QdhMpIrZPTrJumDRxIaecB8DHAygsgO-8PxQKkYx5ESGj6pBl.vZAWJHZoGeNyX9R4?startTime=1572978711000&_x_zm_rtaid=M4Wj53e3QXyaUK9nI6hiQg.1644387258044.8569edd15b9c2bafee5b5a283ad9fa90&_x_zm_rhtaid=108
of using GNUnet instead of DNS
I2P web-of-trust name system
https://geti2p.net/en/docs/naming
(web of trust based)
Crypto-currency-based
https://ens.domains/
https://docs.ens.domains/en/latest/introduction.html
https://www.namecoin.org/
https://en.wikipedia.org/wiki/Namecoin
Do you need to buy a name to host a site on clearnet?
Do you need to buy an static IP to host a site on clearnet,
or does a dynamic IP suffice?
What about dynamic DNS?
https://en.wikipedia.org/wiki/Dynamic_DNS
Do you need to buy act actual machine? A virtual one?
Do you need to buy an HTTPS certificate?
Do you need to buy anything else?
What about overlay layers or darknets for simple free hosting?
https://en.wikipedia.org/wiki/I2P
https://en.wikipedia.org/wiki/Tor_(anonymity_network)
Can one circumvent DNS editing as a censorship technique?
Can one block sites at all with common darknets?
What is the easiest way to set up an independent site on your own
hardware, or a VPS you rent?
Static websites:
https://onionshare.org/
http://lldan5gahapx5k7iafb3s4ikijc4ni7gx5iywdflkba5y2ezyg6sjgyd.onion/
sudo dnf install tor
pip3 install --upgrade onionshare-cli --user
echo "cool publically accessible website" >index.html
onionshare-cli --website --public index.htmlYou could even host a website like this on your phone,
in under 10 minutes:
https://onionshare.org/mobile/#download
Anywhere that had an internet connection,
you could leave your phone plugged in an host a website there…
https://medium.com/axon-technologies/hosting-anonymous-website-on-tor-network-3a82394d7a01
Interactive backend easily possible with tor process and Apache.
https://geti2p.net/en/faq#myI2P%20Site
Today:
Theoretical difficulties with P2P and their solutions (general).
An overview of protocols and services provided by P2P overlay
applications (general).
High level protocol specification for an example P2P application
(BitTorrent).
There are many P2P protocols.
BitTorrent is just one we will review today.

Examples:

File distribution problem: Client server vs. P2P
Upload/download capacity is limited resource!
Question:
How much time to distribute file (size F),
from one server, to N peers?
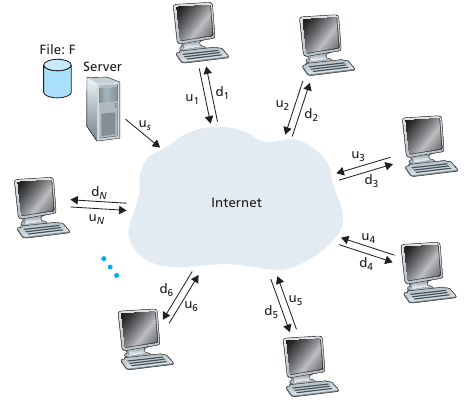
Let’s first determine the distribution time for the client-server
architecture,
which we denote by Dcs. In the client-server architecture,
none of the peers aids in
distributing the file. We make the following observations:
The server must transmit one copy of the file to each of the N
peers.
Thus, the server must transmit N * F bits.
Since the server’s upload rate is us,
the time to distribute the file must be at least (N * F) /
us
Server transmission
Must sequentially send (upload) a number (N) of file (F) copies:
Server upload rate:
us
Time to send one copy:
F / us
\[ time = \frac{bits}{\frac{bits}{seconds}} \]
\[ time = bits * \frac{seconds}{bits} \]
Time to send N copies:
(N * F) / us
Let d min denote the download rate of the peer with the lowest
download rate,
that is, dmin = min{d1, d2, …,
d~N}.
The peer with the lowest download rate,
cannot obtain all F bits of the file in less than F / dmin
seconds.
Thus the minimum distribution time is at least F / dmin
That however, will almost never be the real time,
as the server must distribute to many peers.
Client: each client must download file copy.
Time to distribute F to N clients using client-server
approach:
Dcs > max{ (N * F) / us, F / dmin
}
Max numerator increases linearly with N.
Question: how much time to distribute file (size F)
from one server to N peers?
At the beginning of the distribution, only the server has the
file.
To get this file into the community of peers, the server must send each
bit of the file at least once into its access link.
Thus, the minimum distribution time is at least F / us
Unlike the client-server scheme, a bit sent once by the server may not
have to be sent by the server again, as the peers may redistribute the
bit among themselves.
Server transmission
Must upload at least one copy.
Time to send one copy:
F / us
As with the client-server architecture, the peer with the lowest
download rate,
cannot obtain all F bits of the file in less than F / dmin
seconds.
Thus the minimum distribution time is at least F / dmin
Unlike with the client-server model, with p2p,
this could actually (and often is) the server’s bandwidth
contribution.
Client: each client must download file copy.
Min client download time: F / dmin
The total upload capacity of the system as a whole,
is equal to the upload rate of the server,
plus the upload rates of each of the individual peers, that is:
utotal = us + u1 + … +
uN
The system must deliver (upload) F bits to each of the N peers,
thus delivering a total of N * F bits.
This cannot be done at a rate faster than utotal.
Thus, the minimum distribution time is also at least:
(N * F) / (us + u1 + … + uN).
Clients: as aggregate, each individual (i) must
download N * F bits
Max upload rate (limiting max download rate) is us +
sum(ui)
Time to distribute F to N clients using P2P
approach:
DP2P > max{ F / us, F / dmin, (N *
F) / (us + sum(ui)) }
Max numerator increases with N
But, so does the denominator,
since each peer provides service capacity
Net client upload rate = u
F / u = 1 hour
us = 10u
dmin >= us
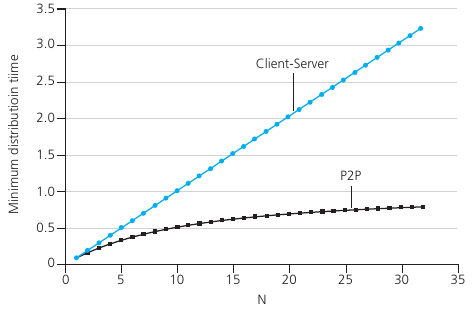
P2P vs Client server
For the P2P architecture the minimal distribution time is always
lesser,
compared to the distribution time of the client-server
architecture.
It is also less than a fixed duration, above some number of
peers N!
Applications with the P2P architecture can be self-scaling.
This scalability is a direct consequence of peers being
re-distributors,
as well as consumers of bits.
Standard protocol,
many clients (Vuze, BigglyBt, I2P-Snark, Bittorrent-official, etc.,
),
and versions of tracker software (some server-based trackers).
File divided into 256Kb chunks (or other equal size).
Peers in torrent send/receive file chunks.
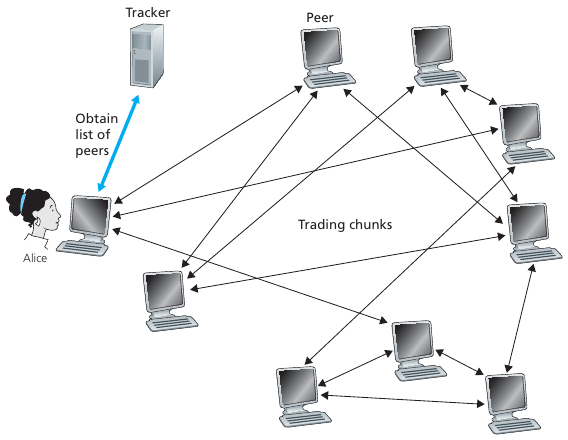
Tracker:
Tracks peers participating in torrent (or DHT).
Runs their own choice of tracker software.
Used to be only a server-side operation, now also can be P2P!
Torrent:
Meta-data and group of peers exchanging chunks of a file.
Client:
Uploads and downloads files.
Runs their own client torrent software.
Process:
Alice arrives, chooses a torrent, and using the torrent meta-data,
obtains a list of peers from tracker server (or distributed
tracker),
and finally begins exchanging file chunks with peers in torrent.
++++++++++++++++ Cahoot-02-11
Peer joining torrent:
After joining:
Churn:
Requesting chunks:
Ask: Why rarest first?
Discussion question:
Why not just be a leech (download but not contribute)?
How might you design a protocol with incentives?
What might an incentive look like?
Should you build incentives into protocols?
Do people follow incentives?
How do we put a kink in the wires of those who don’t contribute
enough,
slowing down their transfers,
to encourage every peer to reciprocate?
Sending chunks: tit-for-tat incentives
https://en.wikipedia.org/wiki/Tit_for_tat
Overview:
(1) Alice “optimistically un-chokes” a new participant, Bob, in hopes
that reciprocates
(2) Alice becomes one of Bob’s top-four providers; Bob
reciprocates
(3) Bob becomes one of Alice’s top-four providers
All this results in higher upload rate, finding better trading partners, and getting file faster !
Sharing is caring…
Due to risk or costs in internet speed or throughput,
individuals could potentially download, but not upload.
An interesting read, game theory in software design and
CompSci:
http://bittorrent.org/bittorrentecon.pdf
General (not BitTorrent specific)
++++++++++++++++ Cahoot-02-12
Review: dictionaries, maps, and hash tables
Simple database with (key, value) pairs:
key: human name;
value: social security number
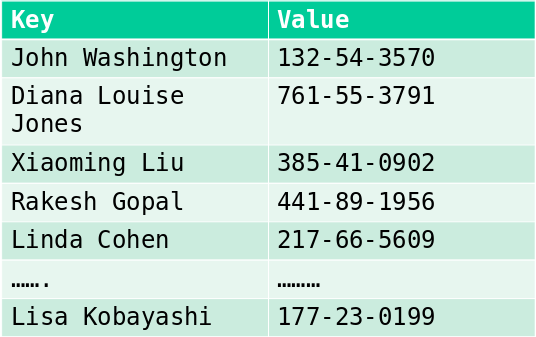
key = hash(original key)
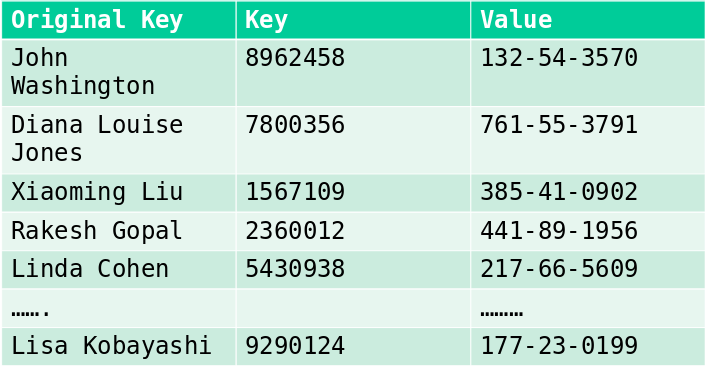
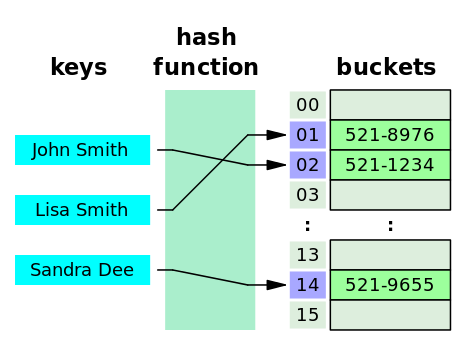
Note: There are potentially two distributed
databases (or merged into one) in some p2p networks:
1. Routing table for overlay network peers, who are defined by their
addresses
2. Database of torrents: addresses/peers
It’s easy to keep a database on a server,
but how do we increase the censorship resistance and robustness?
(ComputerNetworkingEssentials.pdf, 128.17.123.38)DHT
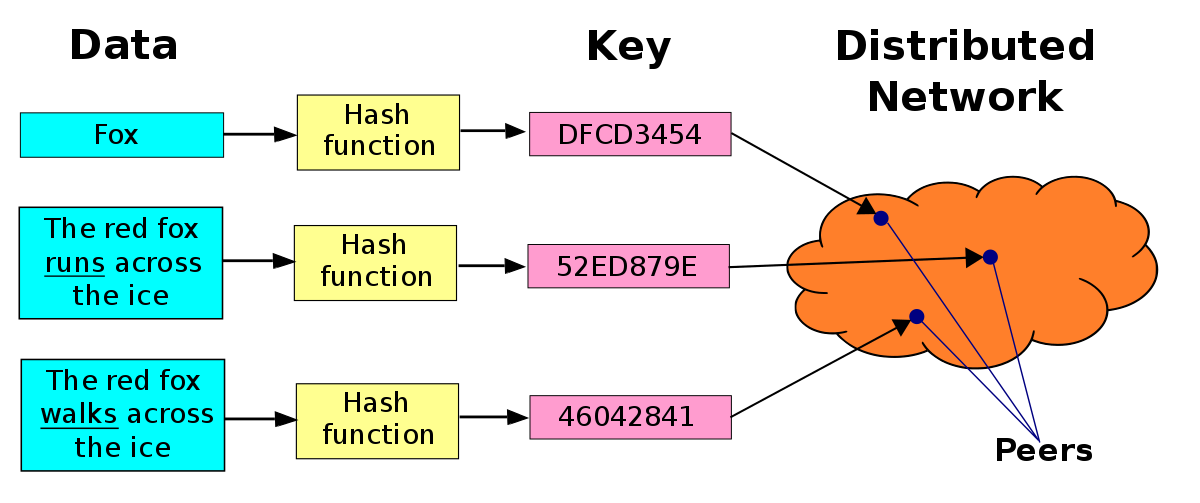
Problem
Solution
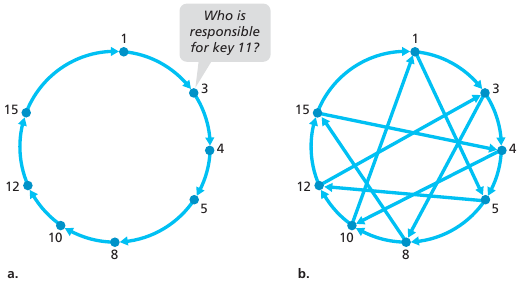
Peers come an go, and the network must adapt.
Example, peer 5 abruptly leaves, or is disconnected
Handling peer churn:
Example: peer 5 abruptly leaves:
https://en.wikipedia.org/wiki/Bittorrent
https://wiki.wireshark.org/BitTorrent
http://bittorrent.org/beps/bep_0000.html
https://www.bittorrent.org/beps/bep_0003.html (show in
class)
https://en.wikipedia.org/wiki/Torrent_file (show in
class)
https://en.wikipedia.org/wiki/Magnet_URI_scheme
Show a real torrent file, map to specifications.
For example, https://ftp.qubes-os.org/iso/Qubes-R4.1.0-x86_64.torrent
BitTorrent protocol: two main transport level choices
The motivation for uTP is for BitTorrent clients to not disrupt internet connections, while still utilizing the unused bandwidth fully.
When using regular TCP connections, BitTorrent quickly fills up the send buffer, adding multiple seconds delay to all interactive traffic.
More detail on this when we get to the details of TCP buffers (next major topic is transport layer).
0 4 8 16 24 32
+-------+-------+---------------+---------------+---------------+
| type | ver | extension | connection_id |
+-------+-------+---------------+---------------+---------------+
| timestamp_microseconds |
+---------------+---------------+---------------+---------------+
| timestamp_difference_microseconds |
+---------------+---------------+---------------+---------------+
| wnd_size |
+---------------+---------------+---------------+---------------+
| seq_nr | ack_nr |
+---------------+---------------+---------------+---------------+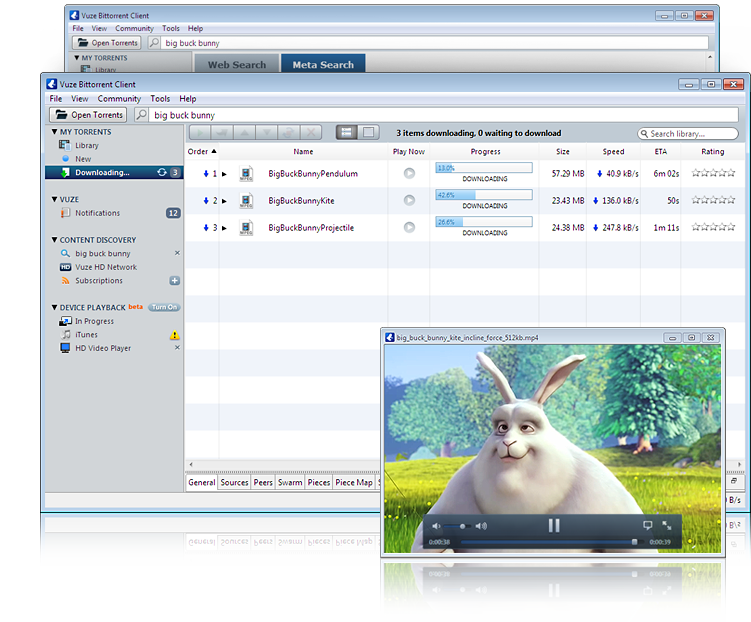
Show/demo: Wireshark downloading Linux ISO with transmission
Next: 03-Transport.html